Lambda 参数的局部变量语法
JDK 增强提案 323允许在隐式类型 lambda 表达式的中使用“var”关键字。
先来看 显式类型 的 Lambda 表达式。在下面的代码中,参数 l 和 s 的类型 被明确声明(List<String> 和 String):
(List<String> l, String s) -> l.add(s);然而,Java 编译器具备 类型推导 的能力,可以从上下文中自动推断变量类型,因此,省略类型 也是允许的,即 隐式类型 写法:
(l, s) -> l.add(s);从 Java 11 开始,您可以使用Java 10 中引入的“var”关键字来代替显式类型:
(var l, var s) -> l.add(s);那么问题来了,既然可以完全省略类型,为什么还要写 var 呢?—— 答案在于注解。
Java 规定:注解必须作用于类型,而不能直接标注变量名。在 Java 10 之前,若要给 Lambda 参数添加注解,只能采用显式类型的方式,例如:
(@Nonnull List<String> l, @Nullable String s) -> l.add(s);而在 Java 11 中,我们可以使用 var 进行简化,使代码更紧凑且不失表达力:
(@Nonnull var l, @Nullable var s) -> l.add(s);值得注意的是,var 不能随意滥用,也不能与显式类型混用,必须保持 “全显式”、“全省略” 或 “全 var” 的一致性。
此外,var 的使用也有诸多限制,具体如下表所示:
| 限制 | 是否允许 | 说明 |
|---|---|---|
| 方法参数 | ❌ | 不能用 var 作为方法参数类型 |
| 成员变量 | ❌ | 只能用于局部变量 |
null 初始化 |
❌ | var 不能赋值 null,必须有明确类型 |
| Lambda 表达式 | ❌ | 不能推断 Lambda 返回类型 |
try-with-resources |
❌ | 不能用于 try-with-resources 语句的资源变量 |
| 泛型推断 | ✅ | 但不能用于匿名泛型实例 |
HTTP 客户端(标准)
Java 11:HttpClient 让 HTTP 操作更简洁
在 Java 11 之前,使用 JDK 自带的 API 发送 HTTP POST 请求需要编写大量样板代码。以下示例基于 Java 8,使用 BufferedReader.lines() 将响应读取为 Stream,并借助 Collectors 组合成 String。如果是在 Java 8 之前,代码行数会更多,逻辑也更繁琐:
public String post(String url, String data) throws IOException {
URL urlObj = new URL(url);
HttpURLConnection con = (HttpURLConnection) urlObj.openConnection();
con.setRequestMethod("POST");
con.setRequestProperty("Content-Type", "application/json");
// 发送数据
con.setDoOutput(true);
try (OutputStream os = con.getOutputStream()) {
byte[] input = data.getBytes(StandardCharsets.UTF_8);
os.write(input, 0, input.length);
}
// 处理HTTP错误
if (con.getResponseCode() != 200) {
con.disconnect();
throw new IOException("HTTP response status: " + con.getResponseCode());
}
// 读取响应
String body;
try (InputStreamReader isr = new InputStreamReader(con.getInputStream());
BufferedReader br = new BufferedReader(isr)) {
body = br.lines().collect(Collectors.joining("\n"));
}
con.disconnect();
return body;
}JDK 11 引入了全新的 HttpClient(HttpClient 由JDK 增强提案 321 定义)类,让 HTTP 请求的编写更加简洁、直观。我们可以用 HttpClient 改写上述代码,使其更加清晰易读:
public String post(String url, String data) throws IOException, InterruptedException {
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.header("Content-Type", "application/json")
.POST(BodyPublishers.ofString(data))
.build();
HttpResponse<String> response = client.send(request, BodyHandlers.ofString());
if (response.statusCode() != 200) {
throw new IOException("HTTP response status: " + response.statusCode());
}
return response.body();
}相比 HttpURLConnection,HttpClient 在 API 设计上更加现代化,避免了大量的样板代码,使 HTTP 操作更加简洁优雅。同时,它支持 同步 和 异步 两种编程模型,并且支持 HTTP/2 和 WebSocket,是 Java 11 之后处理 HTTP 请求的推荐方案。
HttpClient 的灵活性
新的 HttpClient API 还提供了多种方式来处理 HTTP 请求和响应。例如,在上面的例子中,我们通过 BodyPublishers.ofString() 发送 String 数据。除此之外,我们还可以使用:
ofByteArray()发送 字节数组ofFile()直接从 文件 读取数据ofInputStream()处理 输入流
同样,BodyHandlers 也提供了多种响应处理方式,比如:
ofString()直接将响应转换为 字符串ofByteArray()以 字节数组 形式获取响应ofFile()直接将响应 存入文件ofInputStream()以 输入流 形式读取
这些特性让 HttpClient 变得更加强大和灵活,可以适应不同的场景需求。
异步请求:让网络调用更高效
除了同步方式,HttpClient 还支持 异步调用,使得网络请求不会阻塞主线程,而是返回一个 CompletableFuture,从而提高程序的响应速度。例如,我们可以用异步方式实现 post 方法:
public void postAsync(String url, String data, Consumer<String> consumer, IntConsumer errorHandler) {
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.header("Content-Type", "application/json")
.POST(BodyPublishers.ofString(data))
.build();
client.sendAsync(request, BodyHandlers.ofString())
.thenAccept(response -> {
if (response.statusCode() == 200) {
consumer.accept(response.body());
} else {
errorHandler.accept(response.statusCode());
}
});
}在这个实现中:
sendAsync()以 非阻塞方式 发送请求,并返回CompletableFuture。.thenAccept(response -> { ... })用于在请求完成后处理响应。- 通过 回调函数(
Consumer<String>和IntConsumer),我们可以灵活处理 成功 和 失败 的情况。
相比传统的同步方式,异步 HTTP 请求可以显著提高吞吐量,尤其是在 高并发 或 IO 密集型 应用场景中。
以下方法并未在单独的 JDK 增强提案中提出,而是作为其他提案的附带功能实现的
新的 Collection.toArray() 方法
在 Java 中,Collection 接口提供了两个 toArray() 方法,可用于将集合转换为数组。下面的示例展示了这两个方法的用法,并以 String 列表为例:
List<String> list = List.of("foo", "bar", "baz");
Object[] strings1 = list.toArray();
String[] strings2a = list.toArray(new String[list.size()]);
String[] strings2b = list.toArray(new String[0]);第一个 toArray() 方法(不带参数)返回的是 Object 数组。这是因为 Java 的泛型存在类型擦除([关于泛型详见:说说Java泛型]),在运行时 list 的具体类型信息无法保留。
第二个 toArray() 方法允许传入一个目标数组。如果这个数组的长度不小于集合的大小,那么集合元素会被存储到这个数组中(如 strings2a)。否则,方法会创建一个合适大小的新数组(如 strings2b)。
Java 12 新增 toArray() 方法
从 未来Java 12 开始,我们可以使用构造方法引用来创建目标数组:
String[] strings = list.toArray(String[]::new);这种方式允许 Collection 使用传入的数组构造函数创建合适大小的数组。不过,该方法的使用场景相对较少。它在 Collection 接口中的默认实现如下:
default <T> T[] toArray(IntFunction<T[]> generator) {
return toArray(generator.apply(0));
}这个方法本质上是先创建一个空数组,然后调用原有的 toArray() 方法。
String 类的增强方法
在 Java 11 版本中,String 类新增了一些实用方法,使得字符串处理更加便捷。
1. strip()、stripLeading() 和 stripTrailing()
String.strip() 方法用于去除字符串两端的空白字符。你可能会问:“我们已经有 trim() 了,为什么还需要 strip()?”——两者的行为有所不同。
trim()仅删除ASCII 码值 ≤ U+0020 的字符,例如普通空格(' ')、制表符(\t)、换行符(\n)、回车符(\r)等。strip()则会删除所有被 Unicode 标准定义为空白字符的字符,包括一些特殊的空格符号(如U+2002,一个与字母 'n' 一样宽的空格)。
此外,该方法还有两个变体:
stripLeading():仅去除前导空白字符stripTrailing():仅去除尾部空白字符
2. isBlank()
String.isBlank() 方法用于检查字符串是否仅包含空白字符(即 Character.isWhitespace() 认定的字符)。示例:
System.out.println(" ".isBlank()); // true
System.out.println("hello".isBlank()); // false这比 trim().isEmpty() 更直观,且更符合日常开发需求。
3. repeat()
String.repeat(int count) 允许我们重复一个字符串若干次。例如:
System.out.println(":-) ".repeat(10));:-) :-) :-) :-) :-) :-) :-) :-) :-) :-)这个方法特别适合快速生成重复字符(比如填充字符、分隔线等)。
4. lines()
String.lines() 方法可以按行拆分字符串,并返回 Stream<String>。示例:
Stream<String> lines = "foo\nbar\nbaz".lines();
lines.forEachOrdered(System.out::println);// 输出:
// foo
// bar
// bazFiles.readString()和writeString()
自Java 6以来,读写文本文件的功能不断简化。在Java 6中,我们必须打开一个FileInputStream,用InputStreamReader和BufferedReader包装它,然后将文本文件逐行加载到StringBuilder中(或者省略BufferedReader,以char[]块读取数据),并在finally块中关闭读取器和InputStream。幸运的是,我们有像Apache Commons IO这样的库,它们用FileUtils.readFileToString()和writeFileToString()方法为我们完成了这项工作。
在Java 7中,我们可以使用Files.newBufferedWriter()和Files.newBufferedReader()更轻松地创建嵌套的流/读取器或流/写入器组合。并且由于try-with-resources,我们不再需要finally块。然而,仍然需要几行代码:
public static void writeStringJava7(Path path, String text) throws IOException {
try (BufferedWriter writer = Files.newBufferedWriter(path, StandardCharsets.UTF_8)) {
writer.write(text);
}
}
private static String readFileJava7(Path path) throws IOException {
StringBuilder sb = new StringBuilder();
try (BufferedReader reader = Files.newBufferedReader(path, StandardCharsets.UTF_8)) {
String line;
while ((line = reader.readLine()) != null) {
sb.append(line).append('\n');
}
}
return sb.toString();
}Java 11 终于提供了简洁的文件读写方法,使其与第三方库(如 Apache Commons IO)提供的方法类似:
Files.writeString(path, text, StandardCharsets.UTF_8);
text = Files.readString(path, StandardCharsets.UTF_8);相比 Java 7 及更早版本:
- 无需手动创建流
- 代码更加精简
- 更符合直觉
此外,在 Java 18,JEP 400 规范将 UTF-8 设为默认字符集,届时我们甚至可以省略 StandardCharsets.UTF_8 这一参数。
Path.of()
到目前为止,我们通常通过 Paths.get() 或 File.toPath() 来创建 Path 对象。而在 Java 8 中引入的接口默认方法,允许 JDK 开发者将适当的工厂方法直接集成到 Path 接口中。从 Java 11 开始,我们可以通过以下方式创建路径对象:
// 相对路径 foo/bar/baz
Path.of("foo/bar/baz");
Path.of("foo", "bar/baz");
Path.of("foo", "bar", "baz");
// 绝对路径 /foo/bar/baz
Path.of("/foo/bar/baz");
Path.of("/foo", "bar", "baz");
Path.of("/", "foo", "bar", "baz");你可以传入完整的路径或路径的各个部分,并可以根据需要任意组合这些部分。
定义绝对路径时,第一部分必须以 /(在 Linux 和 macOS 上)开头,或者在 Windows 上以驱动器号开头(如 C:)。
Optional.isEmpty()
Java 8 引入了 Optional 类,用于表示可能为空的值。在 Java 11 中,Optional 类新增了 isEmpty() 方法,用于检查 Optional 是否为空。例如:
Optional<String> optional = Optional.of("foo");
System.out.println(optional.isEmpty()); // 输出: false
Optional<String> emptyOptional = Optional.empty();
System.out.println(emptyOptional.isEmpty()); // 输出: trueTimeUnit的convert()方法
Java 11为TimeUnit枚举增加了一个convert()方法,用于将时间单位转换为另一个时间单位。例如:
long minutes = TimeUnit.HOURS.convert(2, TimeUnit.MINUTES);
System.out.println(minutes); // 输出: 120Character.toString(int codePoint)
Java 11为Character类增加了一个toString(int codePoint)方法,用于将Unicode代码点转换为字符串。例如:
String str = Character.toString(0x1F600);
System.out.println(str); // 输出: 😀Pattern.asMatchPredicate()
Java 11为Pattern类增加了一个asMatchPredicate()方法,用于将正则表达式转换为Predicate。例如:
Pattern pattern = Pattern.compile("\\d+");
Predicate<String> predicate = pattern.asMatchPredicate();
System.out.println(predicate.test("123")); // 输出: true
System.out.println(predicate.test("abc")); // 输出: falseFiles.mismatch()
Java 11为Files类增加了一个mismatch()方法,用于比较两个文件的内容,并返回第一个不匹配的字节位置。如果文件内容完全相同,则返回-1。例如:
Path path1 = Path.of("file1.txt");
Path path2 = Path.of("file2.txt");
long mismatch = Files.mismatch(path1, path2);
System.out.println(mismatch); // 输出: 第一个不匹配的字节位置,或-1ProcessHandle的增强
Java 11为ProcessHandle类增加了一些新方法,用于获取进程的详细信息。例如:
ProcessHandle currentProcess = ProcessHandle.current();
System.out.println("Process ID: " + currentProcess.pid());
System.out.println("Is alive: " + currentProcess.isAlive());
System.out.println("Info: " + currentProcess.info());HttpClient的authenticator()方法
Java 11为HttpClient类增加了一个authenticator()方法,用于设置HTTP请求的身份验证信息。例如:
HttpClient client = HttpClient.newBuilder()
.authenticator(new Authenticator() {
@Override
protected PasswordAuthentication getPasswordAuthentication() {
return new PasswordAuthentication("user", "password".toCharArray());
}
})
.build();Epsilon:无操作垃圾收集器
随着 JDK 11 的推出,Java 引入了一个新的垃圾收集器:Epsilon GC。
Epsilon GC 的特点是它什么都不做。它管理堆上的对象分配,但没有垃圾收集过程来回收这些对象。换句话说,它不会自动清理不再使用的内存。
那么,这样一个不收集垃圾的垃圾收集器有什么用呢?
可以想象以下几种场景:
- 性能测试:在微基准测试中,例如,当您比较不同算法的实现时,常规的垃圾收集器可能会干扰测试结果,因为它会影响执行时间,进而扭曲测量结果。通过使用 Epsilon GC,可以排除这些影响,确保更为精准的性能数据。
- 短生命周期应用程序:对于某些应用程序,例如 AWS Lambda 函数,应用程序可能只在几毫秒内运行,垃圾收集的开销会导致不必要的时间浪费。因此,Epsilon GC 可以在这类场景中发挥作用。
- 消除延迟:如果开发者已经充分了解应用程序的内存需求,并且大部分时间内几乎不进行对象分配,Epsilon GC 可以帮助他们实现无延迟的应用程序。
要激活 Epsilon GC,可以在 Java 命令行中使用以下选项(与其他垃圾收集器类似):
-XX:+UseEpsilonGC(Epsilon GC 由JDK 增强提案 318定义 。)
Nest-Based Access Control
Java 11 引入了 Nest-Based Access Control,用于改进嵌套类的访问控制。这意味着,嵌套类可以更灵活地访问其外部类的私有成员。以下是一个简单示例:
public class Outer {
private static class Inner {
private void print() {
System.out.println("Hello from Inner");
}
}
}(这个特性由JDK 增强提案 181定义。)
启动单文件源代码程序
对于由一个类组成的小型 Java 程序,Java 11 引入了一个非常有趣的功能:可以直接编译并执行 .java 文件(),无需单独调用 javac 编译。
,可以使用该命令编译并执行 .java 文件java。
创建一个具有以下名称Hello.java和内容的文件:
public class Hello {
public static void main(String[] args) {
if (args.length > 0) {
System.out.printf("Hello %s!%n", args[0]);
} else {
System.out.println("Hello!");
}
}
}以前,必须javac先使用 编译该程序,然后使用 运行它java:
$ javac Hello.java
$ java Hello Anna
⟶
Hello Anna!从 Java 11 开始,可以省略 javac 步骤,直接通过 java 命令运行 .java 文件:
$ java Hello.java Anna
⟶
Hello Anna!该命令会自动编译源代码并立即执行。
在 Linux 和 macOS 上,甚至可以将其进一步简化,编写可执行的 Java 脚本。只需要确保脚本文件以 #!/usr/bin/java --source 11 开头:
#!/usr/bin/java --source 11
public class Hello {
public static void main(String[] args) {
if (args.length > 0) {
System.out.printf("Hello %s!%n", args[0]);
} else {
System.out.println("Hello!");
}
}
}将该文件重命名并使其可执行:
mv Hello.java Hello
chmod +x Hello
$ ./Hello Anna
⟶
Hello Anna!基于嵌套的访问控制
在使用内部类时,我们Java开发人员经常会面临以下警告:
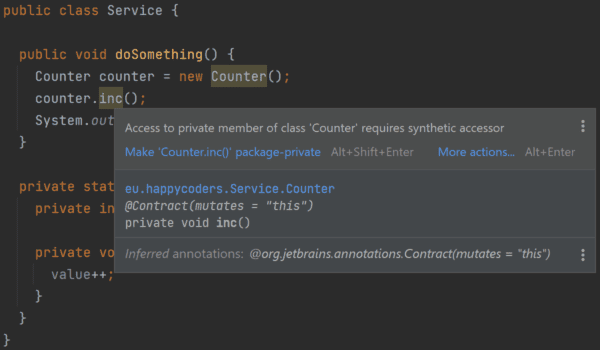
Java语言规范(JLS)允许访问内部类的私有字段和方法。但有个问题,Java虚拟机(JVM)却不允许这样做。
为了处理这个矛盾,Java编译器(直到Java 10)会在访问这些私有字段和方法时,插入一些所谓的“synthetic accessor methods”。这些方法默认是包私有的。
这样一来,那些看似私有的字段和方法就能被整个包访问到,结果就会触发警告。
以前,如果遇到这种情况,你可以自己把相关的成员设置成包私有,或者在Eclipse里使用@SuppressWarnings("synthetic-access")来忽略警告。
不过,从Java 11开始,JDK 增强提案 181对JVM的访问控制机制做了扩展,现在可以直接访问内部类的私有成员,而不需要这些合成访问器了。
如果你之前是因为这个问题把内部类的方法和字段设置为包私有,或者用了@SuppressWarnings,那么升级到Java 11之后,你就可以把这些改动撤回了。
分析工具
Java Flight Recorder(JFR):黑匣子
在开发过程中,我们通常会借助各种工具来分析和修复错误。然而,有些问题只有在应用程序运行时才会出现,而这些问题往往难以复现,导致排查变得异常困难,甚至无从下手。
这时候,Java Flight Recorder(JFR)就能派上用场了。JFR 能够在 Java 应用运行时记录 JVM 的各种数据,并将其保存到文件中,供后续分析使用。
Flight Recorder 作为 Oracle JDK 的商业功能已经存在多年。通过 JDK 增强提案 328,它成为 OpenJDK 的一部分,因此可以免费使用。
如何启动 Flight Recorder?
你可以通过两种方式启动 Flight Recorder。首先,你可以在启动应用程序时使用以下选项:
-XX:StartFlightRecording=filename=<file name>其次,你可以使用 jcmd 在运行的 Java 应用程序中激活 Flight Recorder:
jcmd JFR.start filename=<file name>可以在Oracle 的官方 Flight Recorder 文档中找到更多相关指令信息。
Java Flight Recorder 示例
在以下示例中,假设 31100 是要分析的 Java 应用程序的进程 ID。可以按如下方式启动记录(我们通过可选的 name 参数为记录指定一个名称):
$ jcmd 31100 JFR.start filename=myrecording.jfr name=myrecording
31100:
Started recording 1. No limit specified, using maxsize=250MB as default.
Use jcmd 31100 JFR.dump name=myrecording to copy recording data to file.通常,Flight Recorder 只在特定时间间隔和退出应用程序时将记录保存到指定文件中。但是,也可以通过执行启动时显示的 dump 命令手动保存记录:
$ jcmd 31100 JFR.dump name=myrecording
31100:
Dumped recording "myrecording", 344.8 kB written to:
<path>/myrecording.jfr如果在启动时没有指定 name 参数,你可以将记录编号(在上面的示例中为 1)作为名称。
我们也可以按如下方式停止 Flight Recorder:
$ jcmd 31100 JFR.stop name=myrecording
31100:
Stopped recording "myrecording".如何分析 Flight Recorder 保存的文件?
虽然 JFR 记录了大量的 JVM 运行时数据,但我们还需要额外的工具来分析这些数据……
JDK 任务控制
要查看收集的数据,您需要另一个工具:JDK Mission Control(项目的 GitHub 页面)。
单击“文件/打开文件…”加载分析文件。任务控制中心首先向您显示收集的数据的概览:
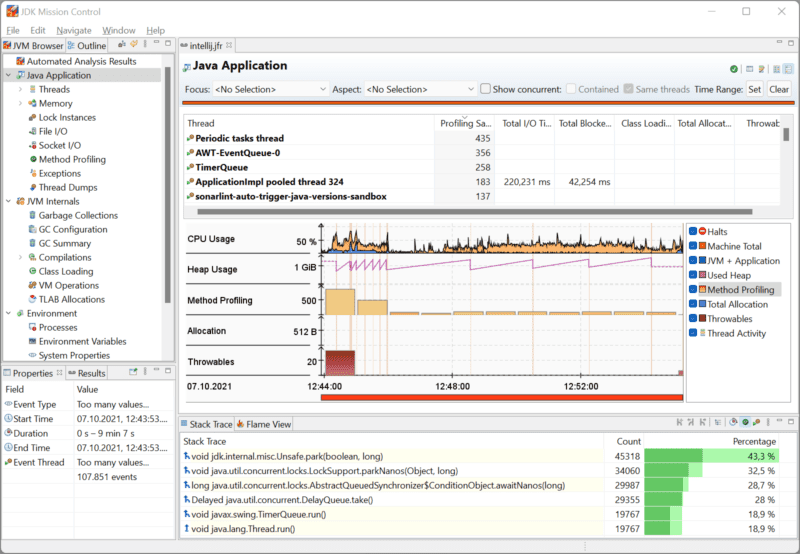
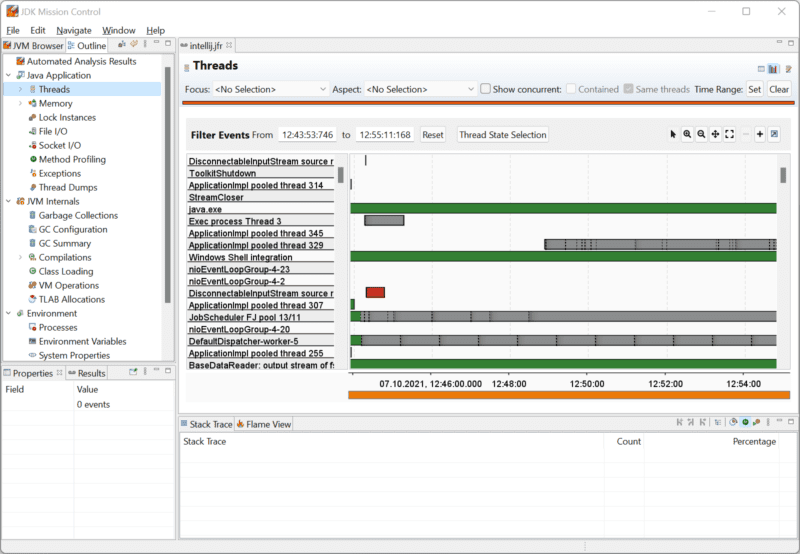
通过左侧的导航,可以深入了解特定区域,例如线程、内存使用、锁等。例如,在“线程”中,可以看到哪些线程在何时运行:
低开销堆分析
在分析内存问题(比如 高垃圾回收延迟 或 OutOfMemoryError)时,堆转储是非常重要的工具。市面上有不少工具可以获取堆上的对象信息,但过去这些工具通常无法追踪对象的创建位置。
JEP 331提案解决了这个问题。它扩展了 Java 虚拟机工具接口(JVMTI),使其能够收集所有对象分配的堆栈跟踪。这样,堆分析工具就可以提供更详细的信息,帮助开发人员更轻松地排查问题。
实验性和预览性功能
ZGC:可扩展的低延迟垃圾收集器(实验性)
ZGC(Z Garbage Collector)是 Oracle 开发的一种新的垃圾收集器,主要目标是将完整 GC(即对整个堆的垃圾回收)暂停时间控制在 10ms 以内,并且相比 G1GC,整体吞吐量下降幅度不超过 15%。
目前,ZGC 仅支持 Linux,可以使用以下 JVM 参数启用:
-XX:+UnlockExperimentalVMOptions -XX:+UseZGCZGC 将在Java 15中达到生产状态。
Java 11 变更与移除的功能
移除 Java EE 和 CORBA 模块
JDK 增强提案 320正式移除了以下模块:
java.xml.ws(JAX-WS)java.xml.bind(JAXB)java.activation(JAF)`java.xml.ws.annotation(通用注解)java.corba(CORBA)`java.transaction(JTA)`- java.se.ee
(用于聚合上述模块的 Java EE 兼容性模块) - jdk.xml.ws
(JAX-WS 工具) - jdk.xml.bind`(JAXB 工具)
这些技术最初是 Java EE 平台的一部分,并在 Java 6 时集成进了 Java SE。Java 9 版本中,它们被标记为“已弃用”,到了 Java 11 终于被彻底移除。
如果升级到 Java 11 后发现缺少这些库,可以通过 Maven 依赖将它们重新引入项目。
弃用 Nashorn JavaScript 引擎
JDK 8 中引入的 JavaScript 引擎“Rhino”在 Java 11 中被JEP 335标记为“计划移除” ,并将在后续版本中被彻底删除。
原因是 ECMAScript(JavaScript 语言标准)和 Node.js 发展迅速,继续维护 Nashorn 变得成本过高。
Pack200 工具和 API 被弃用
Pack200 是 Java 5 引入的一种特殊压缩方式,专门用于 .class 和 .jar 文件,早期主要用于减少带宽消耗。然而,随着网络速度的提升(百兆宽带已经普及),这种复杂的压缩算法已显得多余。
因此,该工具在JDK 增强提案 336中被标记为“已弃用” ,未来某个版本中可能会移除。
JavaFX 独立发布
从 Java 11 开始,JavaFX(及 javapackager 工具)不再随 JDK 一起发布。需要从JavaFX 主页将其作为单独的 SDK 下载。
Java 11 其他变更(非必需了解,但可能有用)
支持 Unicode 10
JDK 增强提案 327扩展了 Java 11 对 Unicode 10.0 的支持,主要影响 String 和 Character 类,例如 String.toUpperCase()、toLowerCase() 以及 Character.getName() 等方法。
示例(Unicode 码点 0x1F929 代表 🤩 表情):
System.out.println("name = " + Character.getName(0x1F929));
System.out.println("block = " + Character.UnicodeBlock.of(0x1F929));在 Java 10 及以下版本中,代码输出如下:
name = null
block = nullJava 11 则知道这个新表情符号—— 😉
name = GRINNING FACE WITH STAR EYES
block = SUPPLEMENTAL_SYMBOLS_AND_PICTOGRAPHS优化 AArch64(ARM 64位)指令
JDK 增强提案 315对 AArch64(64 位 ARM 处理器)进行了优化,增强了部分 JDK 类库方法的执行效率。如:
- 新增三角函数(sin、cos、tan)和对数函数(log)的汇编级指令优化
- 提升
String.compareTo()和String.indexOf()的执行效率
支持 TLS 1.3 加密协议
此前,JDK 仅支持以下安全协议:
- SSL 3.0
- TLS 1.0、1.1、1.2
- DTLS 1.0、1.2(Datagram Transport Layer Security)
JEP 332新增了对 TLS 1.3 的支持,提升了安全性。
ChaCha20 和 Poly1305 加密算法
JEP 329为 JDK 添加了 ChaCha20 和 Poly1305 两种加密算法,在 TLS 1.3 等协议中被广泛使用,能提供更高效的加密性能。进行高速加密和解密。
与 Curve25519 和 Curve448 的密钥协议
JEP 324新增了 Curve25519 和 Curve448 椭圆曲线算法,加快对称密钥的加密与解密。
动态类文件常量
JDK 增强提案 309扩展了 .class 文件格式,新增 CONSTANT_Dynamic 常量,使编程语言设计者和编译器开发者有了更灵活的选择。