说说Java泛型
简单安全。一方面,由于在编译时会进行类型检查,因此提高了安全性,另一方面,在编译阶段就可以把错误报出来,从而减轻了程序员的调试工作量。
性能的提升。以容器为例,在没有泛型的时候,由于容器返回的类型都是Object类型,因此需要根据实际情况将返回值强制转换为期望的类型。在引入泛型以后,由于容器中存储的类型在声明的时候可以确定,因此对容器的操作不需要进行类型转换,这样做的好处是一方面增强了代码的可读性,降低了程序出错的可能性,另一方面也提高了程序运行的效率。
3) 避免强制类型转换
4) 限定类型
5) 实现一些特别的编程技巧
Java在JDK1.5中引入泛型这一新特性,泛型的本质是参数化类型,也就是说,可以把数据类型指定为一个参数,这个参数类型可以用在类、接口和方法的创建中。
泛型基础:略
数组和泛型容器
要区分数组和泛型容器,那么就需要先理解以下三个概念:协变性(covariance)、逆变性(contravariance)和无关性(invariant)。
若类A是类B的子类,则记作A≦B。设有变换f(),则有以下定律:
-
当A≦B时,有f(A)≦f(B),则称变换f()具有协变性。
-
当A≦B时,有f(B)≦f(A),则称变换f()具有逆变性。
-
如果以上两者皆不成立,那么称变换f()具有无关性。
在Java语言中,数组具有协变性,而泛型具有无关性,示例代码如下所示:

以上这两行代码,数组正常编译通过,而泛型抛出了编译期错误,应用之前提出的概念对代码进行分析,可知以下推论:
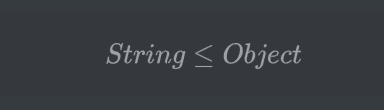
数组的变换可以表达为f(A)=A[],通过之前的示例
可以得出以下推论:
f(String) = String[] 以及 f(Object) = Object[]通过代码验证,String[]≦Object[]是成立的,由此可见,数组具有协变性。ArrayList泛型的变换可以表达为f(A)=ArrayList``<A>
得出以下推论:
f(String) = ArrayList<String> 以及 f(Object) = ArrayList<Object>最终得出结论,数组具备协变性,而泛型具备无关性。
所以,为了让泛型具备协变性和逆变性,Java引入了有界泛型的概念。
除了协变性的不同,数组还是具象化的,而泛型不是。
什么是具象化(也可以称之为具体化,物化)?在《Java语言规范》里,明确地规定了具象化类型的定义:
完全在运行时可用的类型被称为具象化类型(refiable type),会做这种区分是因为有些类型会在编译过程中被擦除,并不是所有的类型都在运行时可用。它包括:
非泛型类声明,接口类型声明。
所有泛型参数类型为无界通配符(仅用‘?’修饰)的泛型参数类。
原始类型。
基本数据类型。
其元素类型为具象化类型的数组。
嵌套类(内部类、匿名内部类等,例如java.util.HashMap.Entry),并且嵌套过程中的每一个类都是具象化的。
无论是在编译时还是运行时,数组都能确切地知道自己所属的类型。但是泛型在编译时会丢失部分类型信息,在运行时,它又会被当作Object处理。
Java的泛型最后都被当作上界 (? extend Type )
引申1:数组具备协变性,是Java语言的一个缺陷,因为极少有地方需要用到数组的协变性,甚至,使用数组的协变会引起不易检查的运行时异常,参见下面代码:
Object[] array = new String[10];
array[0]=1;很明显,上述代码会在运行期抛出异常:java.lang.ArrayStoreException。由于数组与泛型的这些区别,在Java语言中,数组和泛型是不能混合使用的。参见下面代码:
List<String>[] genericListArray = new ArrayList<String>[10];
T[] genericArray = new T[];它们都会在编译期抛出Cannot create a generic array错误。这是因为数组要求类型是具象化的,而泛型恰好不是。
换言之,数组必须清楚地知道自己内部元素的类型,并且会一直保存这个类型信息,在添加元素的时候,该信息会被用于做类型检查,而泛型的类型是不确定的。所以,在编译器层面就杜绝了这个问题的发生。这在《Java语言规范》里有明确地说明:
If the element type of an array were not reifiable,the virtual machinecould not perform the store check described in the preceding paragraph.This is why creation of arrays of non-reifiable types is forbidden. Onemay declare variables of array types whose element type is not reifiable,but any attempt to assign them a value will give rise to an uncheckedwarning.
如果数组的元素类型不是具象化的,那么虚拟机将无法应用在前面章节里描述过的存储检查。这就是为什么创建(实例化)非具象化的数组是不允许的。你可以定义(声明)一个元素类型是非具象化的数组类型,但任何试图给它分配一个值的操作,都会产生一个unchecked warning。
存储检查:这里涉及Array的基本原理,可以自行参阅《Java语言规范》
泛型具有无关系。
泛型擦除
泛型的使用使得代码的重用性增强。例如,只需要实现一个List接口,就可以根据实际需求向List里面存储String、Integer或其他自定义类型,而不需要实现多个List接口(专门存放String的List接口,专门存放Interger的List接口),那么泛型到底是如何实现的呢?
在目前主流的编程语言中,编译器主要有以下两种处理泛型的方法:
(1)Code specialization使用这种方法,每当实例化一个泛型类的时候都会产生一份新的字节代码,例如,对于泛型ArrayList,当使用ArrayList
(2)Code sharing使用这种方式,会对每个泛型类只生成唯一的一份目标代码,所有泛型的实例会被映射到这份目标代码上,在需要的时候执行特定的类型检查或类型转换。C++中的模板(template)是典型的Code specialization实现。C++编译器会为每一个泛型类实例生成一份执行代码。执行代码中integer list和string list是两种不同的类型。这样会导致代码膨胀,不过有经验的C++程序员可以有技巧地避免代码膨胀。
Code specialization另外一个弊端是在引用类型系统中,浪费空间,因为引用类型集合中元素本质上都是一个指针,没必要为每个类型都产生一份执行代码。而这也是Java编译器中采用Code sharing方式处理泛型的主要原因。这种方式显然比较省空间,而Java就是采用这种方式来实现的。
如何将多种泛型类型实例映射到唯一的字节码中呢?Java是通过类型擦除来实现的。在学习泛型擦除之前,需要首先明确一个概念:Java的泛型不存在于运行时。这也是为什么有人说Java没有真正的泛型的原因了。
泛型擦除(类型擦除)是指在编译器处理带泛型定义的类、接口或方法时,会在字节码指令集里抹去全部泛型类型信息,泛型被擦除后在字节码里只保留泛型的原始类型(raw type)。类型擦除的关键在于从泛型类型中清除类型参数的相关信息,然后在必要的时候添加类型检查和类型转换的方法。
原始类型是指抹去泛型信息后的类型,在Java语言中,它必须是一个引用类型(非基本数据类型),一般而言,它对应的是泛型的定义上界。
示例:<T>中的T对应的原始泛型是Object,<T extends String>
类型擦除现象
static class TypeErasureSample<T>{
public T v1;
public T v2;
public String v3;
}
public static void main(String[] args) throws Exception {
TypeErasureSample<String> type = new TypeErasureSample<String>();
//反射设置v2的值为整数
Field v2 = TypeErasureSample.class.getDeclaredField("v2");
v2.set(type,1);
for (Field f :TypeErasureSample.class.getDeclaredFields()){
System.out.println(f.getName()+":"+f.getType());
}
/*这里报错
java.lang.ClassCastException: java.lang.Integer cannot be cast to java.lang.String
*/
System.out.println(type.v2);
}
v1和v2的类型被指定为泛型T,但是通过反射发现,它们实质上还是Object,而v3原本定义的就是String,和前两项比对,可以证明反射本身并无错误。
代码在输出type.v2的过程中抛出了类型转换异常,这说明了两件事情:
①为v2设置整型数已经成功(可以自行写一段反射来验证)。
②编译器在构建字节码的时候,一定做了类似于(String)type.v2的强制转换,关于这一点,可以通过反编译工具(工具为jd-gui)验证,结果如下所示:
public static void main(final String[] args) throws Exception {
final EncryptAspect.TypeErasureSample<String> type = (EncryptAspect.TypeErasureSample<String>)new EncryptAspect.TypeErasureSample();
final Field v2 = EncryptAspect.TypeErasureSample.class.getDeclaredField("v2");
v2.set(type, 1);
for (final Field f : EncryptAspect.TypeErasureSample.class.getDeclaredFields()) {
System.out.println(f.getName() + ":" + f.getType());
}
System.out.println((String)type.v2);
}由此可见,如果编译器认为type.v2有被声明为String的必要,那么都会加上(String)强行转换。可以使用下面的代码来验证上述的分析:
Object o = type.v2;
String s = type.v2;后者会抛出类型转换异常,而前者是正常执行的。由此可见,泛型类型参数在编译的时候会被擦除,也就是说虚拟机中只有普通类和普通方法,而没有泛型。正因为如此,在创建泛型对象的时候,最好指明类型,这样编译器就能够尽早地做参数的类型检查。
引申1:类型检查是针对引用的还是实际对象的?
类型检查是针对引用的,而不是变量实际指向的对象。
擦除带来的问题
-
泛型类型变量不能是基本数据类型
-
类型的丢失
class Test{ public void f(List-list); public void f(List- list); } 上述代码中,编译器认为这个类中有两个相同的方法(方法参数也相同)被定义,因此会报错,主要原因是在声明List
<String>和List<Integer>- catch中不能使用泛型异常类
假设有一个泛型异常类的定义
MyException<T>try{} catch(MyExceptione1) {....} catch ( MyException<Integer>e2){…}因为擦除的存在,
MyException<String>和MyException<Integer>都会被擦除为MyException<Object>此外,也不允许在catch子句中使用泛型变量,示例代码如下所示:
publicvoid test(T t){ try{...} catch(T e){//编译报错 ... }catch(IOException e){ ... } } 假设上述代码能通过编译,由于擦除的存在,T会被擦除为Throwable。由于异常捕获的原则为:先捕获子类类型的异常,再捕获父类类型的异常。上述代码在擦除后会先捕获Throwable,再捕获IOException,显然这违背了异常捕获的原则,因此这种写法是不允许的。
- 泛型类的静态方法与属性不能使用泛型
由于泛型类中的泛型参数的实例化是在实例化对象的时候指定的,而静态变量和静态方法的使用是不需要实例化对象的,显然这二者是矛盾的。如果没有实例化对象,而直接使用泛型类型的静态变量,那么此时是无法确定其类型的。