局部变量类型推断("var")
从 Java 10 开始,我们可以使用关键字 var 来声明局部变量(局部意味着在方法内部)。例如,以下定义是允许的:
var i = 10;
var hello = "Hello world!";
var list = List.of(1, 2, 3, 4, 5);
var httpClient = HttpClient.newBuilder().build();
var status = getStatus();相比之下,这是经典表示法的定义:
int i = 10;
String hello = "Hello world!";
List<Integer> list = List.of(1, 2, 3, 4, 5);
HttpClient httpClient = HttpClient.newBuilder().build();
Status status = getStatus();你在多大程度上使用 var 可能会在许多团队中引发长时间的讨论。如果 a) 它显著更短,并且 b) 我可以在代码中清楚地看到数据类型,我会使用它。在上面的例子中,这将在第 3 行和第 4 行(对于 List 和 HttpClient)中适用。经典表示法在这两种情况下都要长得多。而右侧的赋值——即 List.of() 和 HttpClient.newBuilder().build()——让我清楚地看到了数据类型。
在以下情况下,我会避免使用 var:
- 在第 1 行,你并没有节省一个字符;在这里,我会坚持使用
int。 - 在第 2 行,
var只比String稍微短一点——所以在这里我也会使用String。但如果团队决定使用var,我也能理解。 - 在第 5 行,我会坚持使用旧表示法。否则,我无法一眼看出
getStatus()返回的是什么。是int?String?枚举?复杂的值对象?还是数据库中的 JPA 实体?
有关何时使用 var 何时不使用的更详细讨论,请参阅官方风格指南。最重要的是,在团队内达成一致的使用方式。
(局部变量类型推断定义在JDK增强提案286.)
不可变集合
通过 Collections.unmodifiableList()、unmodifiableSet()、unmodifiableMap()、unmodifiableCollection()——以及另外四个用于排序和导航集合和映射的变体——Java 集合框架提供了为集合类创建不可变包装器的可能性。以下是一个示例:
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
List<Integer> unmodifiable = Collections.unmodifiableList(list);如果我们现在尝试通过包装器添加一个元素,我们会得到一个 UnsupportedOperationException:
unmodifiable.add(4);
⟶Exception in thread "main" java.lang.UnsupportedOperationException
at java.base/java.util.Collections$UnmodifiableCollection.add(...)
at ...然而,包装器并不阻止我们修改底层列表。所有后续的更改也会在包装器中可见。这是因为包装器并不包含列表的副本,而是一个视图:
list.add(4);
System.out.println("unmodifiable = " + unmodifiable);
⟶unmodifiable = [1, 2, 3, 4]List.copyOf()、Set.copyOf() 和 Map.copyOf()
在 Java 10 中,我们现在还可以创建集合的不可变副本。为此,我们有静态接口方法 List.copyOf()、Set.copyOf() 和 Map.copyOf()。如果我们创建了这样的副本,然后修改原始集合,更改将不再影响副本:
List<Integer> immutable = List.copyOf(list);
list.add(4);
System.out.println("immutable = " + immutable);
⟶immutable = [1, 2, 3]尝试更改副本——就像使用 unmodifiableList() 时一样——会得到 UnsupportedOperationException:
immutable.add(4);
⟶Exception in thread "main" java.lang.UnsupportedOperationException
at java.base/java.util.ImmutableCollections.uoe(...)
at java.base/java.util.ImmutableCollections$AbstractImmutableCollection.add(...)
at ...注意:如果你需要一个可修改的列表副本,你可以随时使用复制构造函数:
List<Integer> copy = new ArrayList<>(list);Collectors.toUnmodifiableList()、toUnmodifiableSet() 和 toUnmodifiableMap()
使用 Collectors.toList()、toSet() 和 toMap() 创建的收集器将 Stream 的元素收集到可变列表、集合和映射中。以下示例展示了这些收集器的使用以及随后对结果的修改:
List<Integer> list = IntStream.rangeClosed(1, 3).boxed().collect(Collectors.toList());
Set<Integer> set = IntStream.rangeClosed(1, 3).boxed().collect(Collectors.toSet());
Map<Integer, String> map = IntStream.rangeClosed(1, 3).boxed()
.collect(Collectors.toMap(Function.identity(), String::valueOf));
list.add(4);
set.add(4);
map.put(4, "4");
System.out.println("list = " + list);
System.out.println("set = " + set);
System.out.println("map = " + map);正如你所期望的那样,程序会产生以下输出(尽管集合和映射的元素可能以不同的顺序出现):
list = [1, 2, 3, 4]
set = [1, 2, 3, 4]
map = {1=1, 2=2, 3=3, 4=4}在 Java 10 中,添加了 Collectors.toUnmodifiableList()、toUnmodifiableSet() 和 toUnmodifiableMap() 方法,现在允许我们将流元素收集到不可变的列表、集合和映射中:
List<Integer> list = IntStream.rangeClosed(1, 3).boxed().collect(Collectors.toUnmodifiableList());
Set<Integer> set = IntStream.rangeClosed(1, 3).boxed().collect(Collectors.toUnmodifiableSet());
Map<Integer, String> map = IntStream.rangeClosed(1, 3)
.boxed()
.collect(Collectors.toUnmodifiableMap(Function.identity(), String::valueOf));尝试修改这样的列表、集合或映射会得到 UnsupportedOperationException。(此扩展没有 JDK 增强提案。)
Optional.orElseThrow()
Optional 在 Java 8 中引入,提供了 get() 方法来检索 Optional 包装的值。在调用 get() 之前,你应该始终使用 isPresent() 检查是否存在值:
java
Optional<String> result = getResult();
if (result.isPresent()) {
System.out.println(result.get());
}如果 Optional 为空,get() 会抛出 NoSuchElementException。为了尽量减少意外异常的风险,IDE 和静态代码分析工具会在没有 isPresent() 的情况下使用 get() 时发出警告:
IntelliJ 对没有 isPresent() 的 Optional.get() 的警告

然而,也有一些情况下,这样的异常是期望的。以前,必须向代码中添加适当的 @SuppressWarnings 注解以抑制警告。Java 10 提供了更优雅的解决方案,即 orElseThrow() 方法:
该方法是 get() 方法的精确副本——只是名称不同。由于从名称中可以清楚地看出该方法可能会抛出异常,因此排除了误解。静态代码分析不再将其使用批评为代码异味。以下是两种方法的源代码对比:
public T get() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
public T orElseThrow() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}(此扩展没有 JDK 增强提案。)
基于时间的发布版本控制
在版本格式从 Java 8 到 9 从有些晦涩的 1.8.0_291 更改为更易读的 9.0.4 之后,JEP 322 在 Java 10 中添加了发布日期——并为 Java 11 提前添加了 "LTS"(长期支持)。命令 java -version 在 Java 8 到 11 中返回以下答案:
Java 8:
$ java -version
java version "1.8.0_291"Java 9:
$ java -version
java version "9.0.4"Java 10:
$ java -version
java version "10.0.2" 2018-07-17Java 11:
$ java -version
java version "11.0.11" 2021-04-20 LTS迄今为止,版本控制方案没有进一步的变化。
G1 的并行 Full GC
在 JDK 9 中,,G1(garbage-first) 垃圾收集器取代了并行收集器作为默认的 GC。
虽然并行 GC 可以在应用程序运行时并行执行完整的垃圾收集(即清理堆的所有区域),但 G1 直到现在都无法做到这一点。G1 必须暂时停止应用程序("stop-the-world"),导致明显的延迟。
由于 G1 的设计目标是尽可能避免完整收集,因此这很少成为问题。
在 Java 10 中,通过 JDK JDK增强提案307,G1 收集器的完整垃圾收集现在也已并行化。最坏情况下的延迟(暂停时间)达到了并行收集器的水平。
应用程序类数据共享
由于许多 Java 开发者不熟悉它,我想简要地解释一下类数据共享(不带 "应用程序" 前缀)。
类数据共享
当 JVM 启动时,它会从文件系统加载 JDK 类库(在 JDK 8 之前从 jre/lib/rt.jar 文件;自 JDK 9 以来从 jmods 目录中的 jmod 文件)。在此过程中,类文件从存档中提取,转换为特定于架构的二进制形式,并存储在 JVM 进程的主内存中:

如果在同一台机器上启动了多个JVM,则会重复此过程。每个JVM在内存中保留其类库的副本:
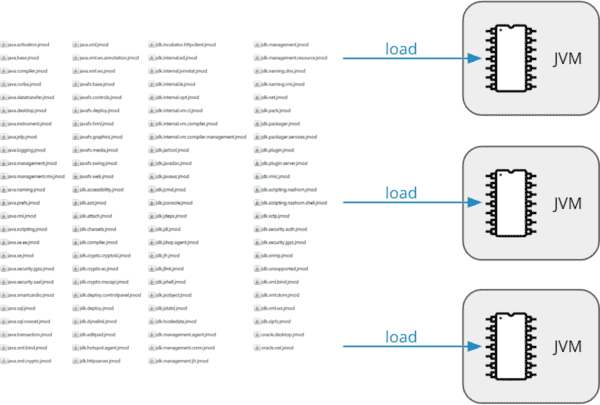
类数据共享(CDS)有两个目标:
- 减少JVM的启动时间。
- 减少JVM的内存占用。
类数据共享的工作原理如下:
- 使用命令java
-Xshare:dump,首先创建一个名为classes.jsa的文件(JSA代表Java共享归档)。此文件包含当前体系结构的二进制格式的完整类库。 - 当JVM启动时,操作系统使用内存映射I/O将此文件“映射”到JVM的内存中。首先,这比加载jar或jmod文件更快。其次,操作系统只将文件加载到RAM中一次,为每个JVM进程提供同一内存区域的只读视图。
下图应说明这一点:
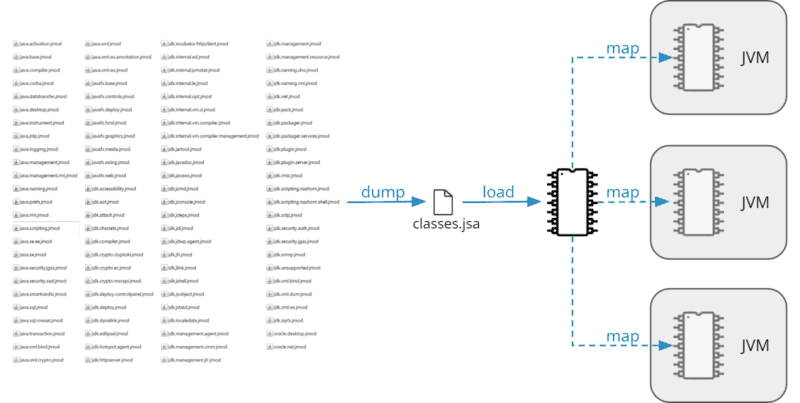 使用Class-Data Sharing加载JDK类库
使用Class-Data Sharing加载JDK类库
应用程序类-数据共享-逐步实现
应用程序类数据共享(也称为“应用程序CDS”或“AppCDS”)扩展了CDS,不仅可以将JDK类库存储在JSA文件中,还可以将应用程序的类存储在JSA文件中,并在JVM进程之间共享它们。
我将通过一个简单的例子向你展示这是如何工作的(你也可以在这个GitHub存储库中找到源代码):
以下两个Java文件位于src/eu/happycoders/appcds目录中:
Main.java:
package eu.happycoders.appcds;
public class Main {
public static void main(String[] args) {
new Greeter().greet();
}
}Greeter.java:
package eu.happycoders.appcds;
public class Greeter {
public void greet() {
System.out.println("Hello world!");
}
}我们编译并打包这些类,然后启动主类:
javac -d target/classes src/eu/happycoders/appcds/*.java
jar cf target/helloworld.jar -C target/classes .
java -cp target/helloworld.jar eu.happycoders.appcds.MainCode 我们现在应该看到“Hello World!“欢迎。
要使用应用程序CDS,我们接下来需要创建应用程序使用的类列表。为此,我们运行以下命令(在Windows上,您必须省略反斜杠并将所有内容写在一行中):
java -Xshare:off -XX:+UseAppCDS \
-XX:DumpLoadedClassList=helloworld.lst \
-cp target/helloworld.jar eu.happycoders.appcds.MainCode注意:此命令仅适用于OpenJDK。在Oracle JDK中,您将收到一个警告,指出Application CDS是一个商业功能,您必须首先解锁(使用-XX:+UnlockCommercialFeatures)。所以最好使用OpenJDK!
在你的工作目录中,你现在应该可以找到文件helloworld.lst,它的内容大致如下:
java/lang/Object
java/lang/String
...
eu/happycoders/appcds/Main
eu/happycoders/appcds/Greeter
...
java/lang/Shutdown
java/lang/Shutdown$LockCode如您所见,不仅列出了应用程序的类,还列出了JDK类库的类。
接下来,我们从类列表中创建JSA文件。
(Note:虽然您可以在前面的步骤中将target/classes目录指定为类路径,但下面的步骤仅适用于打包的helloworld.jar文件。
java -Xshare:dump -XX:+UseAppCDS \
-XX:SharedClassListFile=helloworld.lst \
-XX:SharedArchiveFile=helloworld.jsa \
-cp target/helloworld.jarCode 在处理过程中,您将看到一些统计信息,之后,您将在工作目录中找到文件helloworld.jsa。它应该是大约9 MB的大小。
要使用JSA文件,您现在启动应用程序,如下所示:
java -Xshare:on -XX:+UseAppCDS \
-XX:SharedArchiveFile=helloworld.jsa \
-cp target/helloworld.jar eu.happycoders.appcds.MainCode language: plaintext (plaintext)如果一切正常,你应该看到一个“Hello world!“又来了。
下图总结了应用程序类数据共享的工作原理:
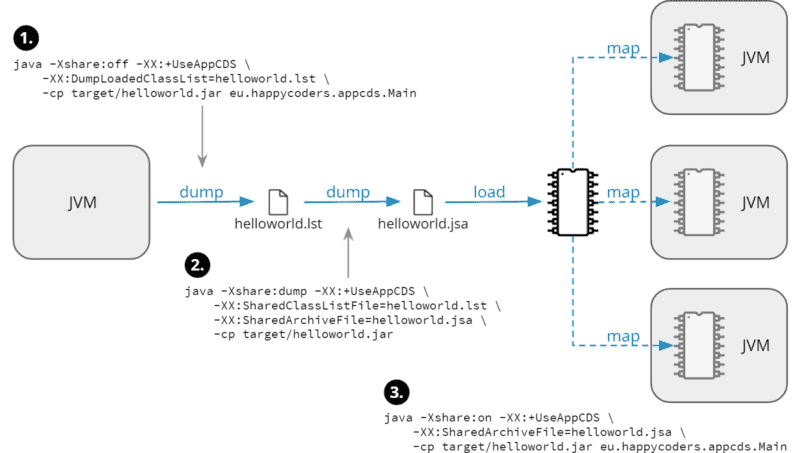
(应用CDS定义在Java增强提案310.)
基于Java的实验性JIT编译器
自Java 9以来,Graal编译器(一个用Java编写的Java编译器)已经作为实验性的提前(AOT)编译器提供。这允许Java程序被编译成本机可执行文件(例如,Windows上的exe文件)。
在Java 10中,JEP 317创造了使用Graal作为即时(JIT)编译器的可能性-至少在Linux/x64平台上。为此,Graal使用了JDK 9中引入的JVM编译器接口(JVMCI)。
您可以通过java命令行上的以下选项激活Graal:
-XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompilerJava 10中的其他更改(作为Java开发人员,您不一定需要知道)
本节列出了我认为每个Java开发人员都不需要详细了解的Java 10功能。
另一方面,至少听说过一次也无妨。:-)
替代存储器设备上的堆分配
通过JEP 316的实现,您现在可以将Java堆(而不是在传统的RAM上)分配到另一个内存设备上,如NV-DIMM(非易失性内存)。
替代存储器必须由操作系统经由文件系统路径(例如,/dev/pmem0),并通过java命令行上的以下选项包含:
-XX:AllocateHeapAt=<path>其他Unicode字符标记扩展
JDK Enhancement Proposal 314添加了所谓的“语言标签扩展”。这些允许在Locale对象中存储以下附加信息:
| 关键 | 描述 | 示例 |
|---|---|---|
| cu | 货币 | ISO 4217货币代码 |
| FW | 一周的第一天 | 2016年10月15日(星期一) |
| RG | 区域覆盖 | uszzzz(美国单位) |
| TZ | 时区 | uslax(洛杉矶),Deber(柏林) |
以下两个扩展自Java 7以来已经存在:
| 关键 | 描述 | 示例 |
|---|---|---|
| CA | 日历 | 格里高利,佛教,中国 |
| nu | 编号系统 | 阿拉伯、罗马 |
下面的示例源代码显示了如何创建一个德语区域设置(“de-DE”),其中美元作为货币(“cu-usd”),星期三作为一周的第一天(“fw-wed”),洛杉矶时区(“tz-uslax”):
Locale locale = Locale.forLanguageTag("de-DE-u-cu-usd-fw-wed-tz-uslax");
Currency currency = Currency.getInstance(locale);
Calendar calendar = Calendar.getInstance(locale);
DayOfWeek firstDayOfWeek = DayOfWeek.of((calendar.getFirstDayOfWeek() + 5) % 7 + 1);
DateFormat dateFormat = DateFormat.getTimeInstance(LONG, locale);
String time = dateFormat.format(new Date());
System.out.println("currency = " + currency);
System.out.println("firstDayOfWeek = " + firstDayOfWeek);
System.out.println("time = " + time);在撰写本文时(柏林晚上8:45),程序打印了以下内容:
currency = USD
firstDayOfWeek = WEDNESDAY
time = 11:45:50 PDT在Java 9中,附加的标记被忽略,程序打印以下内容(40秒后):
currency = EUR
firstDayOfWeek = MONDAY
time = 20:46:30 MESZ由于可能只有极少数Java开发人员必须处理这些细节,我将此扩展放在“其他更改”下。
垃圾收集器接口
垃圾收集器接口(Garbage Collector Interface)
在 JDK 10 中,引入了 JEP 304: Garbage Collector Interface,旨在为 JVM 的垃圾收集器(GC)提供一个清晰的接口,使得开发者能够更轻松地实现和集成新的垃圾收集器。这一改进提高了 JVM 的模块化程度,并为未来的垃圾收集器开发提供了更好的支持。
背景
在 JDK 10 之前,JVM 中的垃圾收集器实现与 JVM 的核心代码紧密耦合。这种紧密耦合使得开发新的垃圾收集器变得复杂,并且增加了维护成本。此外,现有的垃圾收集器代码也难以复用和扩展。
JEP 304 的目标
- 提供清晰的 GC 接口:为垃圾收集器定义一个清晰的接口,使得开发者能够更容易地实现新的垃圾收集器。
- 提高模块化程度:将垃圾收集器的实现与 JVM 的核心代码分离,提高 JVM 的模块化程度。
- 简化维护和扩展:通过标准化接口,简化垃圾收集器的维护和扩展。
实现细节
JDK增强提案304在JDK源代码中引入了一个干净的垃圾收集器接口,将垃圾收集器算法与解释器和编译器隔离开来。
该接口将允许开发人员添加新的GC,而无需调整解释器和编译器的代码库。
- 内存管理:管理堆内存的分配和释放。
- 垃圾回收:执行垃圾回收操作,包括标记、清除和压缩。
- 线程管理:管理垃圾收集器线程的行为。
通过这些接口,开发者可以更容易地实现新的垃圾收集器,并将其集成到 JVM 中。
优点
- 易于实现新的垃圾收集器:通过标准化的接口,开发者可以更轻松地实现和测试新的垃圾收集器。
- 提高模块化程度:垃圾收集器的实现与 JVM 核心代码分离,提高了 JVM 的模块化程度。
- 简化维护和扩展:标准化的接口简化了垃圾收集器的维护和扩展。
示例
以下是一个简单的示例,展示了如何通过垃圾收集器接口实现一个自定义的垃圾收集器:
java
public class CustomGarbageCollector implements GarbageCollector {
@Override
public void collect() {
// 实现垃圾回收逻辑
}
@Override
public void manageMemory() {
// 实现内存管理逻辑
}
@Override
public void manageThreads() {
// 实现线程管理逻辑
}
}根证书
在 JDK 10 中,引入了 JEP 319: Root Certificates,旨在为 OpenJDK 构建提供一个默认的根证书集。这一改进使得 OpenJDK 和 Oracle JDK 在功能上更加一致,特别是在使用 TLS(传输层安全协议)等安全协议时。
背景
在 JDK 8 及更早版本中,Oracle JDK 包含了一组默认的根证书,而 OpenJDK 则没有。这导致在使用 OpenJDK 时,开发者需要手动配置根证书,以支持 TLS 和其他安全协议。这一差异增加了使用 OpenJDK 的复杂性。
JEP 319 的目标
- 提供默认的根证书集:为 OpenJDK 构建提供一个默认的根证书集,使其与 Oracle JDK 在功能上保持一致。
- 简化安全配置:减少开发者在配置 TLS 和其他安全协议时的工作量。
- 增强安全性:通过提供默认的根证书集,提高 OpenJDK 的安全性。
实现细节
JDK 10 在 cacerts 文件中包含了一组默认的根证书。这些证书由公认的证书颁发机构(CA)签发,用于验证 TLS 连接中的服务器证书。开发者可以通过以下命令查看 cacerts 文件中的证书:
keytool -list -keystore $JAVA_HOME/lib/security/cacerts优点
- 一致性:OpenJDK 和 Oracle JDK 在根证书配置上保持一致,减少了开发者在使用不同 JDK 时的困惑。
- 简化配置:开发者无需手动配置根证书,从而简化了安全协议的配置过程。
- 增强安全性:默认的根证书集提供了更高的安全性,确保 TLS 连接的安全性。
示例
以下是一个简单的示例,展示了如何使用默认的根证书集建立 TLS 连接:
java
import javax.net.ssl.HttpsURLConnection;
import java.net.URL;
public class RootCertificatesExample {
public static void main(String[] args) throws Exception {
URL url = new URL("https://example.com");
HttpsURLConnection connection = (HttpsURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.connect();
System.out.println("Response Code: " + connection.getResponseCode());
}
}在JDK增强提案319中,OpenJDK采用了Oracle JDK中包含的根证书。
线程本地握手(Thread-Local Handshakes)
在 JDK 10 中,引入了 JDK Enhancement Proposal 312,这是一项重要的性能优化特性,旨在提高 JVM 的线程管理和调试能力。通过线程本地握手,JVM 可以在不停止所有线程的情况下,对单个线程执行特定的操作,从而减少全局暂停(stop-the-world)的频率和影响。
背景
在多线程应用程序中,JVM 有时需要对所有线程执行某些操作,例如垃圾回收、调试或性能分析。传统上,这些操作需要暂停所有线程(即全局暂停),以确保一致性。然而,全局暂停会导致应用程序的响应时间增加,尤其是在高并发或低延迟要求的场景中。
线程本地握手的作用
线程本地握手允许 JVM 在不暂停所有线程的情况下,对单个线程执行以下操作:
- 线程暂停:暂停单个线程以进行调试或性能分析。
- 栈跟踪:获取单个线程的栈跟踪信息。
- 垃圾回收:在垃圾回收过程中,减少全局暂停的频率。
优点
- 减少全局暂停:通过仅暂停需要操作的线程,减少了应用程序的停顿时间。
- 提高响应性:在高并发或低延迟场景中,应用程序的响应时间得到显著改善。
- 更灵活的调试和性能分析:开发者可以更精确地控制线程的行为,从而提高调试和性能分析的效率。
实现原理
线程本地握手通过向目标线程发送一个“握手”信号来实现。目标线程在安全点(safe point)执行相应的操作,而其他线程可以继续运行。
示例
以下是一个简单的示例,展示了如何在线程本地握手中使用 ThreadMXBean 获取线程的栈跟踪信息:
java
import java.lang.management.ManagementFactory;
import java.lang.management.ThreadMXBean;
public class ThreadLocalHandshakeExample {
public static void main(String[] args) {
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
long[] threadIds = threadMXBean.getAllThreadIds();
for (long threadId : threadIds) {
System.out.println("Thread ID: " + threadId);
for (StackTraceElement element : threadMXBean.getThreadInfo(threadId).getStackTrace()) {
System.out.println("\t" + element);
}
}
}
}移除原生头文件生成工具(Remove the Native-Header Generation Tool)
在 JDK 10 中,引入了 JEP 313: Remove the Native-Header Generation Tool (javah),旨在移除 javah 工具。javah 是一个用于生成 JNI(Java Native Interface)头文件的工具,但随着 javac 已经能够完成这一任务,javah 工具变得冗余,因此被移除。
背景
在 Java 开发中,JNI 允许 Java 代码调用本地(C/C++)代码。为了使用 JNI,开发者需要生成一个头文件,其中包含 Java 类的本地方法声明。javah 工具就是用于生成这些头文件的。
为什么移除 javah?
- 功能冗余:从 JDK 8 开始,
javac已经能够生成 JNI 头文件,因此javah的功能被完全取代。 - 简化工具链:移除
javah可以减少 JDK 中的工具数量,简化开发者的工具链。 - 维护成本:维护一个不再需要的工具会增加 JDK 的维护成本,移除它可以提高开发效率。
在中,javah工具被删除了,开发人员可以使用该工具为JNI生成原生头文件。该功能已集成到Java编译器javac中。
将 JDK 的多个仓库合并为单一仓库(Consolidate the JDK Repositories into a Single Repository)
在 JDK 10 中,引入了 JEP 296: Consolidate the JDK Repositories into a Single Repository,旨在将 JDK 的多个分散的代码仓库合并到一个单一的版本控制系统中。这一改进优化了 JDK 的版本控制,并简化了各个子项目的维护和集成流程。
在 JDK 10 之前,JDK 的代码分布在多个独立的代码仓库中,例如 root、corba、hotspot、jaxp、jaxws、jdk、langtools 和 nashorn。这种分散的结构导致了冗余的源代码库和分支管理,增加了开发和维护的复杂性。
通过将这些子项目整合到一个单一的版本控制系统中,开发者能够更加便捷地访问和贡献代码。这一改动不仅提高了开发效率,还使得 JDK 的发布流程更加灵活和高效。
总结来说,JEP 296 的主要目标是:
- 简化 JDK 的源代码管理。
- 减少冗余的代码库和分支。
- 提高开发者的工作效率和代码贡献的便捷性。
这一改进为 JDK 的后续版本奠定了更加统一和高效的基础。
在JEP 296中,整个JDK源代码被合并到一个monorepo中。monorepo现在允许原子提交、分支和拉取请求,使JDK上的开发变得更加容易。
Java 10中所有更改的完整列表
本文介绍了JDK增强建议中定义的Java 10的所有功能,以及与任何JEP无关的JDK类库的增强。
有关更改的完整列表,请参阅官方Java 10发行说明。
结论
通过var、不可变集合和Optional.orElseThrow(),Java 10为我们提供了一些有用的新工具。G1垃圾收集器现在几乎完全并行工作。通过应用程序类数据共享,我们可以进一步加快应用程序的启动速度并减少其内存占用。如果你想尝试一下,你可以激活用Java编写的Graal编译器。