Redis核心技术
作为Key/Value键值数据库,Redis的应用非常广泛。在之前多年的工作生涯中,我也只是关注了零散的技术点,没有对Redis建立起一套整体观,但只有建立了系统整体观,才能更好地定位问题和解决问题,更重要的是应付面试。
1 KV数据库的基本架构
(1)访问框架
(2)索引模块
(3)操作模块
(4)存储模块
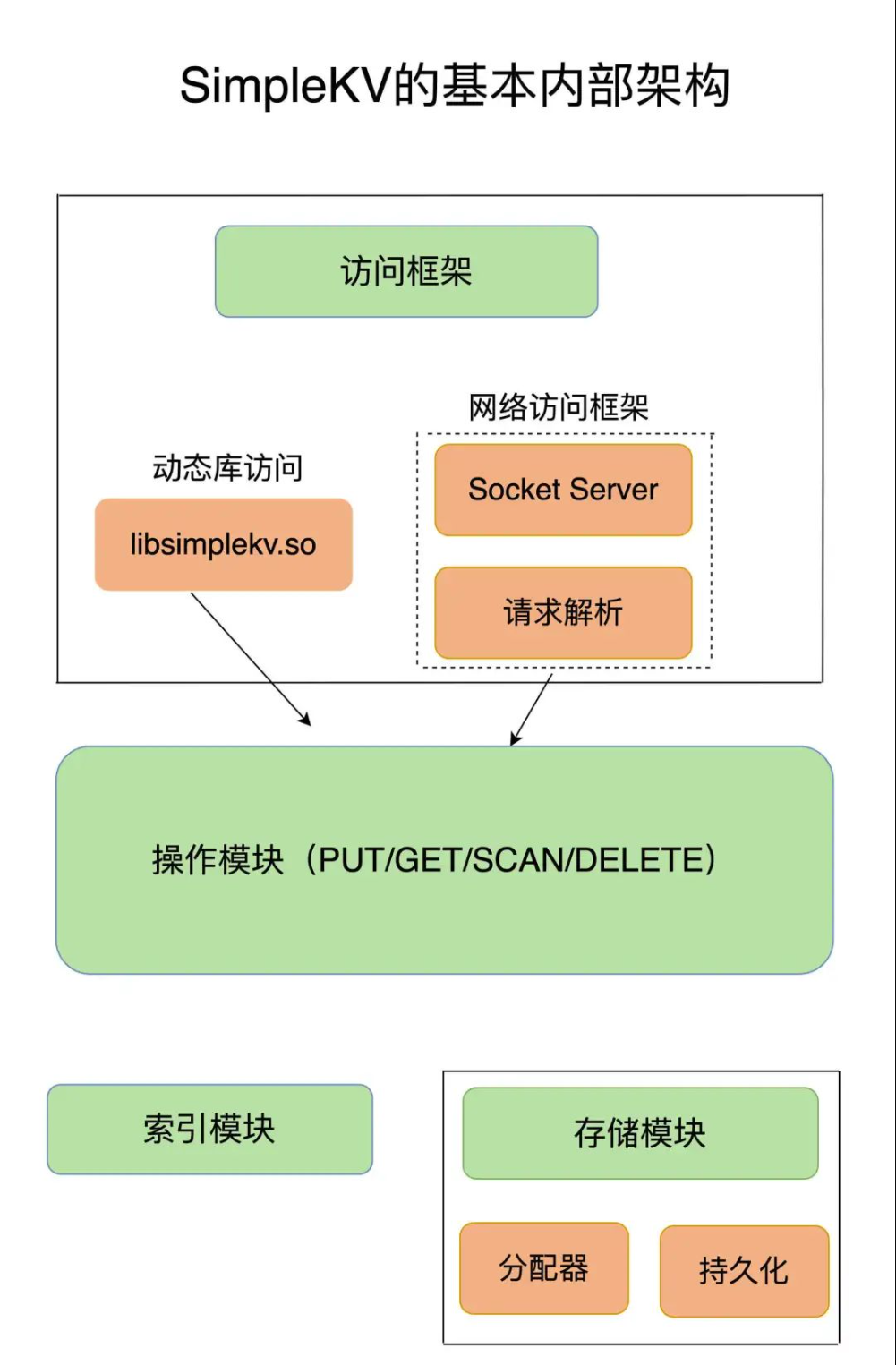
为了支持更加丰富的业务场景,其实 Redis 对这些组件或者功能进行了扩展,或者说是进行了精细优化,从而满足了功能和性能等方面的要求。
下图展示了从SimpleKV到Redis的变化:
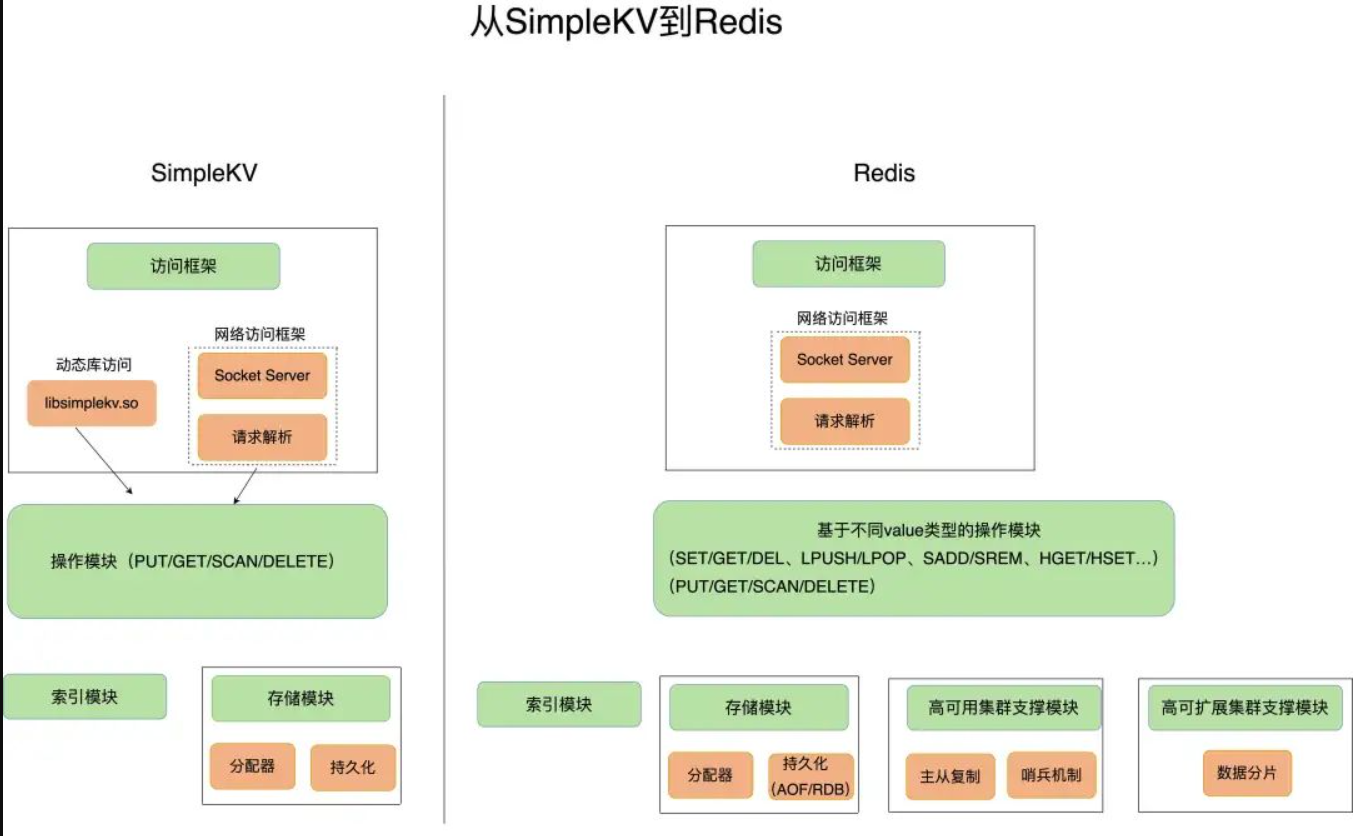
上图中展示了几点变化:
一是Redis主要使用网络框架来进行访问,使得Redis可以作为一个独立的基础网络服务;
二是Redis数据模型中的value类型更加丰富,可以提供更多的接口;
三是Redis扩展了持久化模块,提供日志(AOF)和快照(RDB)。
四是Redis提供了集群的支持,使得HA和可扩展成为可能。
2 Redis的数据结构
Redis之所以“快”,一方面因为它是内存数据库,所有操作都在内存上完成,内存的访问速度本来就快。另一方面则是因为高效的数据结构,使得操作键值效率较高。
总体来说,Redis使用了一个用来保存每个Key/Value的全局哈希表结构,其中Value类型又包括了支持集合类型的双向链表、压缩列表、跳表等五大底层结构。
K/V的组织结构:全局哈希表
Redis使用了一个全局维度的哈希表来保存所有的Key/Value,每个哈希表本质上都是一个数组,这个数组的每个元素称为一个哈希桶。
哈希桶中的元素保存的并不是Value本身,而是指向Value的指针,如下图所示:
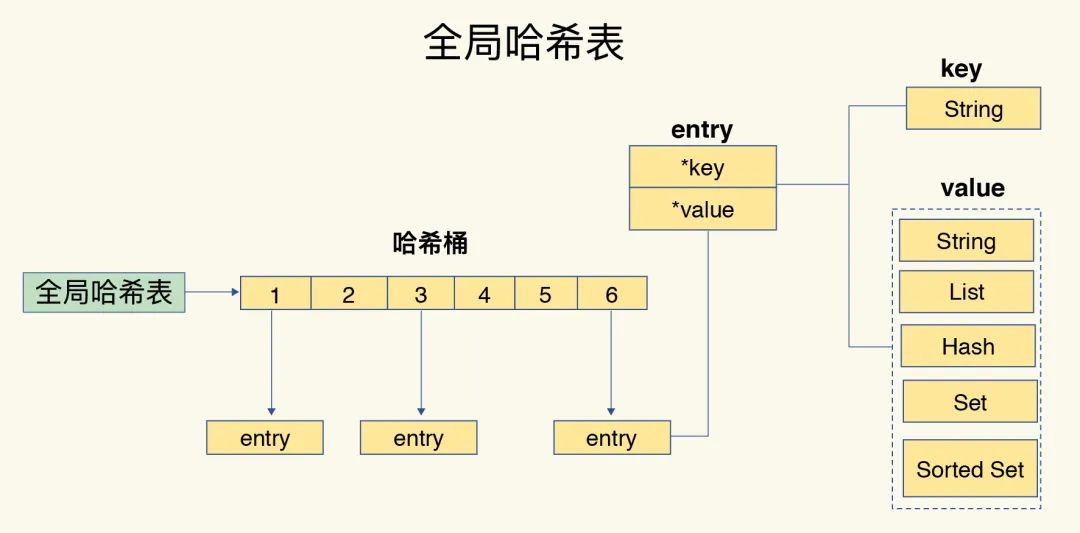
由数据结构的知识可以知道,哈希表的时间复杂度为O(1),因此它非常适合快速查找的场景。
哈希冲突及其解决
当往哈希表中写入的数据变的很多时,哈希冲突问题就会出现。所谓哈希冲突,就是两个Key的哈希值正好落到了同一个哈希桶中(哈希桶的个数毕竟通常少于Key的个数)。
因此,和我们在数据结构课程学到的一致,Redis也采用了链式哈希来解决哈希冲突。所谓链式哈希,就是同一个哈希桶中的多个元素用一个链表来保存,它们之间依次用指针连接,如下图所示:
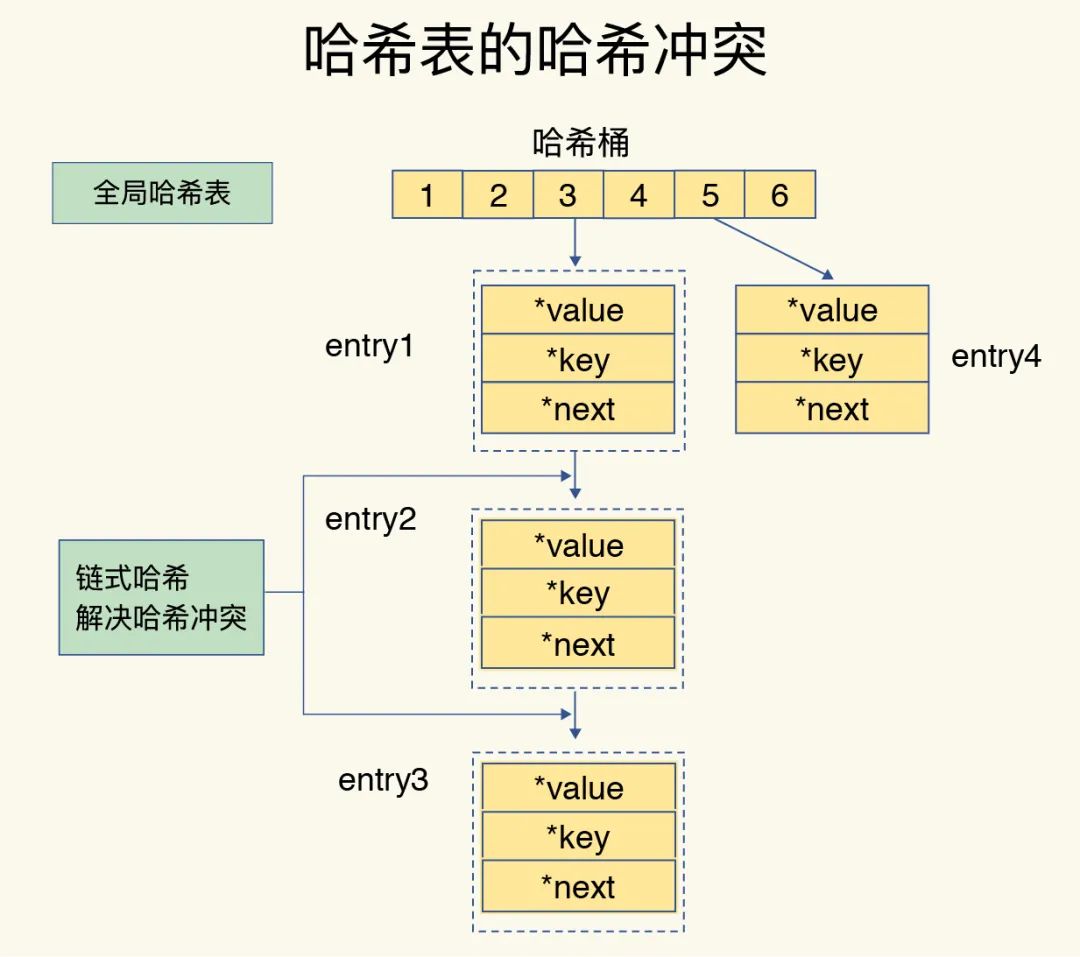
但是,如果哈希表里写入的数据越来越多,哈希冲突链也会进而变得很长,从而导致这个链条上得元素查找耗时长,效率降低。因此,Redis还会对哈希表做rehash操作。所谓rehash,就是增加现有的哈希桶的数量,让逐渐增多的entry元素能够在更多的桶之间分散保存,减少单个桶中的元素数量,从而减少单个桶中的冲突。在具体操作中,Redis会开辟一个新的哈希表(比如:大小为之前的两倍),然后把之前哈希表的数据重新映射到新的哈希表,最后释放之前的哈希表。
But,在拷贝之前哈希表数据到新哈希表时,涉及到数据量过大,有可能会造成Redis的线程阻塞,从而无法服务其他的请求。因此,Redis采用了渐进式哈希的解决方案。简单来说,所谓渐进式哈希就是不一次性把老哈希表中的数据迁移完,而是在每次处理一个请求时,从老哈希表中的第一个索引位置开始,顺带着将这个索引位置上的所有entries拷贝到新哈希表中;等下一个请求时,再顺带拷贝下一个索引位置的entries。如此,便将一次性的大量拷贝的开销,分摊到多次处理请求的过程中,避免了耗时的操作 和 服务的中断。渐进式哈希的示例流程如下图所示:
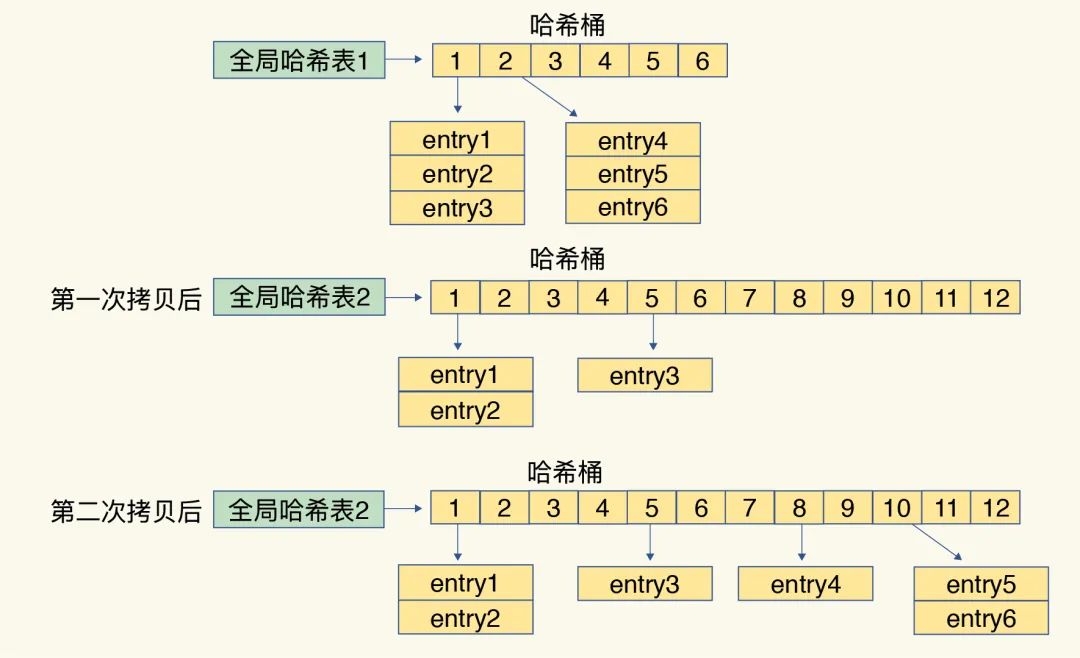
此外,渐进式rehash执行时,除了根据键值对的操作来进行数据迁移,Redis本身还会有一个定时任务在执行rehash,如果没有键值对操作时,这个定时任务会周期性地(例如每100ms一次)搬移一些数据到新的哈希表中,这样可以缩短整个rehash的过程。
底层数据结构概览
Redis的Key/Value是通过哈希表进行组织的,对于String类型,找到哈希桶就可以直接CRUD了,因此O(1)就是String类型的操作复杂度了。
但是,对于集合类型来说,还需要进一步操作。在此之前,我们先了解一下都有哪些底层数据结构。
我们所熟知的String、List、Hash、Sorted Set 和 Set其实只是Redis中数据的保存形式,而一般所说的数据结构其实是它们的底层实现。
如下图所示,Redis的底层数据结构一共有6种,其和常见数据类型的对应关系已经清晰地体现在了下面这张图片里。
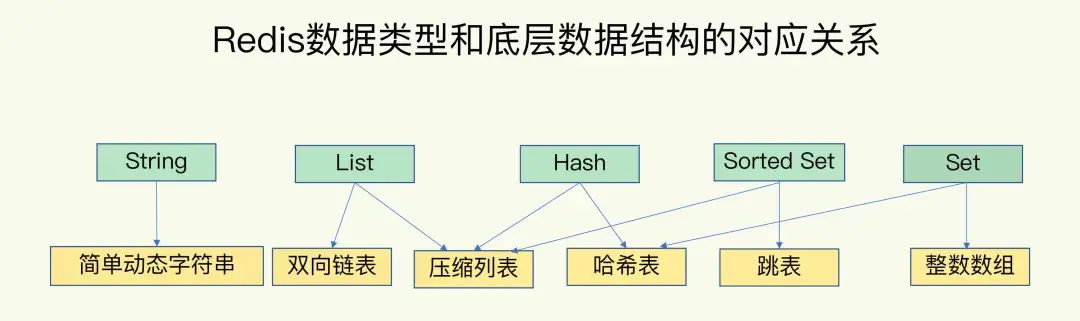
Redis数据类型与底层数据结构 - 来自极客时间
除了String类型的底层实现只有一种,即简单动态字符串。其余数据类型(List、Hash、Sorted Set和Set)都有两种底层实现,他们又被称为集合类型,即一个键对应了一个集合的数据。
底层数据结构复杂度
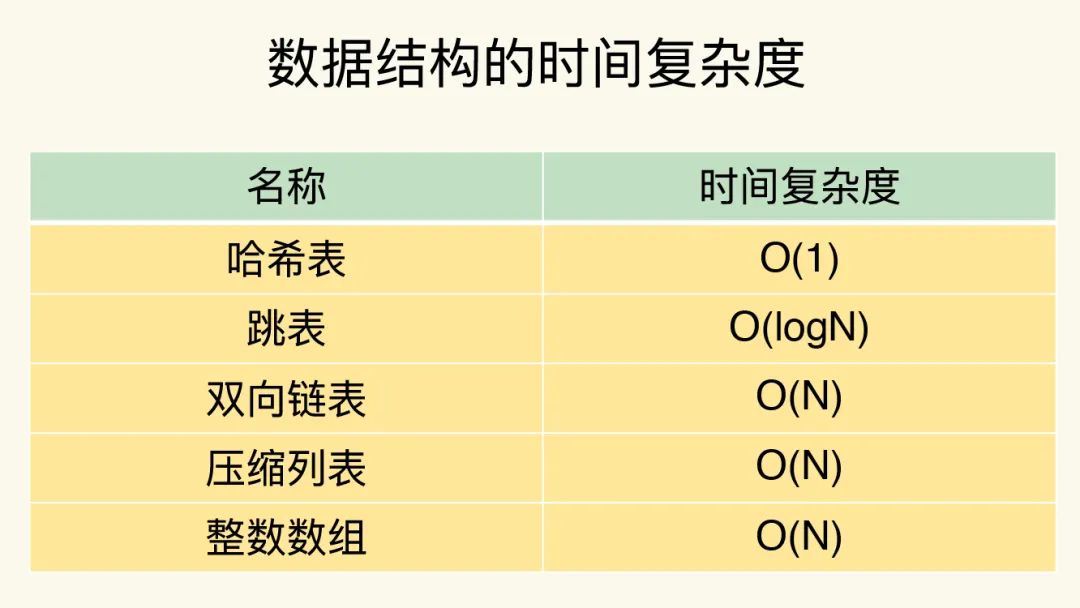
通过上面的描述,我们可以知道哈希表的复杂度是O(1),而数组 和 双向链表 也很常见,其复杂度基本是O(N)。学习过数据结构课程的都知道,O(N)的操作效率并不高,因此Redis引入了压缩列表 和 跳表。虽然压缩列表和跳表并不为我们所熟知,但它俩却是对整数数组和双向链表所做的优化。
首先,来看压缩列表,压缩列表也类似于一个数组,但和数组不同的是,压缩列表在表头有三个字段,分别表示列表长度、列表尾的偏移量 和 列表中entry的个数。压缩列表在表尾还有一个字段,表示列表结束,如下图所示:

由上图可知,在压缩列表中定位第一个和最后一个元素,只需要通过表头三个字段即可直接定位,无须遍历一次,因此查找首元素和尾元素的复杂度为O(1)。而需要查找其他元素时,就只能遍历查找了,此情景的复杂度退化为O(N)。
然后,来看跳表。跳表是在链表的基础之上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位。一个具体的查找案例,如下图所示:
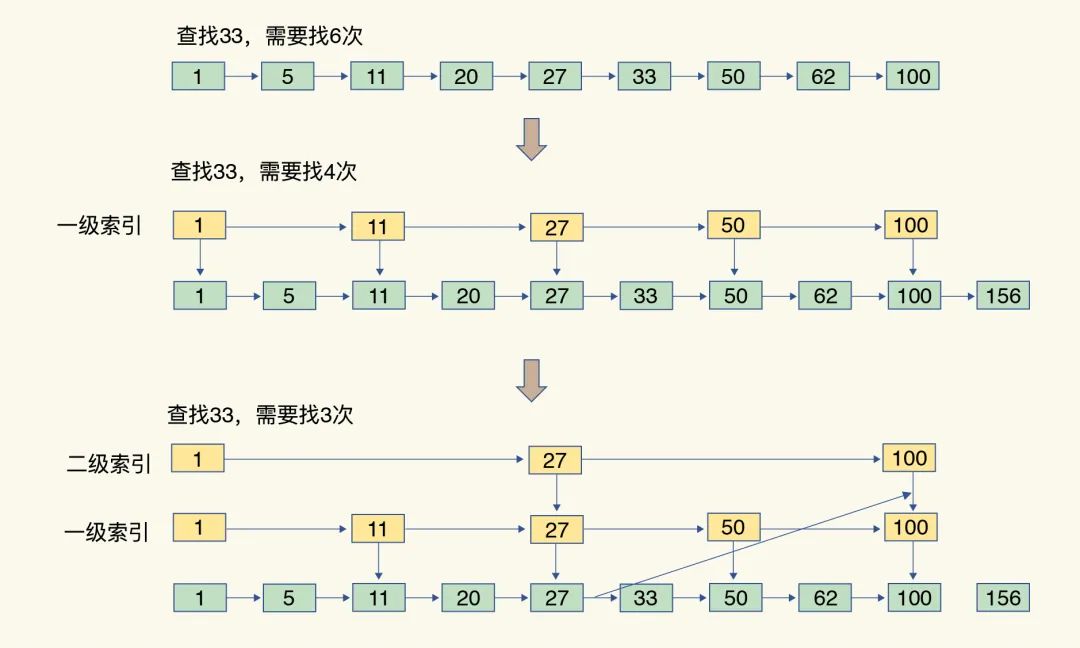
从上图可以看到,这个查找过程其实是在多级索引上跳来跳去,最后定位到具体的要查找的元素。我们常听到,没有什么不是一顿火锅解决不了的事情,如果不行,那就两顿。对于跳表来说,没有什么不是增加索引解决不了的查询,如果不够快,那就再加一级索引。当数据量非常大时,跳表的查找复杂度就是O(logN),学过数据结构的都知道,它比O(N)效率要高。因此,我们也可以知道Sorted Set类型在数据元素较少时采用压缩列表,而一旦超过阈值,就会转为跳表结构来保证查询效率不受影响。