用Python 的Flask实现 RESTful API(学习篇)
- 理解API
- 理解Restful API
- 理解装饰器
- 理解Flask框架
- 使用Python Flask 实现Restful API
API的理解
API(application programming interfaces),即应用程序编程接口。API由服务器(Server)提供(服务器有各种各样的类型,一般我们浏览网页用到的是web server,即网络服务器),通过API,计算机可以读取、编辑网站数据,就像人类可以加载网页、提交信息等。通俗地,API可以理解为家用电器的插头,用户只提供插座,并执行将插头插入插座的行为,不需要考虑电器内部如何运作。从另外一个角度上讲API是一套协议,规定了与外界的沟通方式:如何发送请求和接受响应。
理解RESTful API
RESTful API即满足RESTful风格设计的API,RESTful表示的是一种互联网软件架构(以网络为基础的应用软件的架构设计),如果一个架构符合REST原则,就称它为RESTful架构。RESTful架构的特点:
- 每一个URI代表一种资源;
- 客户端和服务器之间,传递这种资源的某种表现层;把"资源"具体呈现出来的形式,叫做它的"表现层"(Representation)。比如,文本可以用txt格式表现,也可以用HTML格式、XML格式、JSON格式表现,甚至可以采用二进制格式;图片可以用JPG格式表现,也可以用PNG格式表现。
- 客户端通过四个HTTP动词,四个表示操作方式的动词:GET、POST、PUT、DELETE。它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。
理解装饰器
为了理解装饰器,应该先做好三个方面的准备:
- 理解对象:
通过变量和对象的关系理解对象,在python中,如果要使用一个变量,不需要提前进行声明,只需要在用的时候,给这个变量赋值即可。如 a=1,整数1 为一个对象,a 是一个引用,利用赋值语句,引用a指向了对象1;这边形象比喻一下:这个过程就相当于“放风筝”,变量a就是你手里面的“线”,python就跟那根“线”一样,通过引用来接触和拴住天空中的风筝——对象。由于Python一切皆是对象的理念,所以函数也是一个对象。
比如,写一个函数,也可以是说创造了一个函数对象。
def cal(x,y):
result=x+y
return result这时便是创造了一个叫做cal的函数对象。然后就可以使用了
cal(1,2) #直接使用了cal这个函数对象
...........或者.............
calculate=cal #把一个名为calculate的变量指向cal这个函数对象
calculate(1,2)- 理解函数带括弧和不带括弧时分别代表的意思
如果只写一个cal(不带扩号),此时的cal仅仅是代表一个函数对象;当写成cal(1,2)时,就是在告诉编辑器说“执行cal这个cal函数” - 理解可变参数和关键字参数
- 可变参数
定义可变参数和定义一个list或tuple参数相比,仅仅在参数前面加了一个*号。如下,在函数内部,参数numbers接收到的是一个tuple,并且,调用该函数时,可以传入任意个参数,包括0个参数:
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
calc(1,2) # 5- 关键字参数
可变参数允许传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。而关键字参数允许传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。请看示例:
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)
>>> person('Bob', 35, city='Beijing')
name: Bob age: 35 other: {'city': 'Beijing'}
>>> person('Adam', 45, gender='M', job='Engineer')
name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'}现在正式开始理解装饰器了。首先理解为什么需要装饰器呢?
主要原因是装饰器可以起到一个“偷懒”的作用,比如写了很多个简单的函数,现在想知道在运行的时候是哪些函数在执行,并且你又觉得这个没有必要写测试,只是想要很简单的在执行完毕之前给它打印上一句“Start”,那该怎么办呢?你可以这样:
def func_name(arg):
print 'Start func_name'
sentence想想看给每一个函数后面都加上那一句话将是非常的麻烦的。但是有了装饰器就不一样了。
def log(func):
def wrapper(*arg, **kw):
print 'Start%s'%func
return func(*arg,**kw)
return wrapper
@log
def func_a(arg):
pass
@log
def func_b(arg):
pass
@log
def func_c(arg):
pass其中,log函数是装饰器。把装饰器写好了之后,只需要把需要装饰的函数前面都加上@log就可以了。在上一段代码中,我们一次性就给三个函数加上了print语句。下面就来解释下装饰器的原理:log函数返回的是wrapper,wrapper是一个函数对象。func_a=log(func_a)就相当于把fun_a指向了wrapper,由于wrapper可以有参数,于是变量func_a也可以有了参数。
理解Flask框架
一个小的Flask应用
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello World!'
if __name__ == '__main__':
app.run()运行上面代码,在浏览器上输入http://127.0.0.1:5000/,便会看到 Hello World! 字样。
那么,这段代码做了什么?
1.首先导入了Flask类。这个类的实例是WSGI应用程序
2.接下来,我们创建一个该类的实例,第一个参数是应用模块或者包的名称,如果使用单一的模块,应该使用name,因为模块的名称将会因其作为单独应用启动还是作为模块导入而有不同
3.然后,我们使用route()装饰器告诉Flask什么样的URL能够触发我们的函数。
4.这个函数的名字也在生成 URL 时被特定的函数采用,这个函数返回我们想要显示在用户浏览器中的信息。
5.最后使用run()函数来让应用运行在本地服务器上。其中ifname=='main':确保服务器只会在该脚本被Python解释器直接执行的时候才会运行,而不是作为模块导入的时候。
如果启用了调试支持,服务器会在代码修改后自动重新载入,并在发生错误时提供一个相当有用的调试器。启动调试,app.run(debug=True);并且route()装饰器把一个函数绑定到对应的URL上。如下例子
@app.route('/')
def index():
return 'Index Page'
@app.route('/hello')
def hello():
return 'Hello World'其中还是可以构造含有动态部分的URL,要给 URL 添加变量部分,可以把这些特殊的字段标记为
@app.route('/user/<username>')
def show_user_profile(username):
# show the user profile for that user
return 'User %s' % username
@app.route('/post/<int:post_id>')
def show_post(post_id):
# show the post with the given id, the id is an integer
return 'Post %d' % post_id如果Flask能匹配URL,也是可以生成URL的。用url_for()来给指定的函数构造URL。它接受函数名作为第一个参数,也接受对应 URL 规则的变量部分的命名参数。未知变量部分会添加到 URL 末尾作为查询参数。这里有一些例子:
from flask import Flask, url_for
>>> app = Flask(__name__)
>>> @app.route('/')
... def index(): pass
...
>>> @app.route('/login')
... def login(): pass
...
>>> @app.route('/user/<username>')
... def profile(username): pass
...
>>> with app.test_request_context():
... print url_for('index') #/
... print url_for('login') #/login
... print url_for('login', next='/') #/login?next=/
... print url_for('profile', username='John Doe')
... #/user/John%20DoeHTTP(与web应用会话的协议)有许多不同的访问URL方法。默认情况下,路由只回应GET请求,但是通过route()装饰器传递methods参数可以改变这个行为。
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
do_the_login()
else:
show_the_login_form()HTTP 方法(也经常被叫做“谓词”)告知服务器,客户端想对请求的页面 做 些什么。下面的都是非常常见的方法:
- GET(方法)浏览器告知服务器:只 获取 页面上的信息并发给我。这是最常用的方法。
- POST(方法)浏览器告诉服务器:想在 URL 上 发布 新信息。并且,服务器必须确保 数据已存储且仅存储一次。这是 HTML 表单通常发送数据到服务器的方法。
- PUT(方法)类似 POST 但是服务器可能触发了存储过程多次,多次覆盖掉旧值。你可 能会问这有什么用,当然这是有原因的。考虑到传输中连接可能会丢失,在 这种 情况下浏览器和服务器之间的系统可能安全地第二次接收请求,而 不破坏其它东西。因为 POST 它只触发一次,所以用 POST 是不可能的。
- DELETE(方法)删除给定位置的信息。
使用Python Flask 实现Restful API
练习设计以为REST准则为指引,通过不同的请求方法操作资源,标识资源。我们将写一个To Do List 应用,并且设计一个web service。
第一步,规划一个根URL,例如:
http://[hostname]/todo/api/v1.0/上面的URL包括了应用程序的名称、API版本,这是十分有用的,既提供了命名空间的划分,同时又与其它系统区分开来。版本号在升级新特性时十分有用,当一个新功能特性增加在新版本下面时,并不影响旧版本。
第二步,规划资源的URL,这个例子十分简单,只有任务清单。

任务清单
我们定义任务清单有以下字段:
- id:唯一标识。整型。
- title:简短的任务描述。字符串型。
- description:完整的任务描述。文本型。
- done:任务完成状态。布尔值型。
现在我们准备实现第一个web service的入口点
#!flask/bin/python
from flask import Flask, jsonify
app = Flask(__name__)
tasks = [
{
'id': 1,
'title': u'Buy groceries',
'description': u'Milk, Cheese, Pizza, Fruit, Tylenol',
'done': False
},
{
'id': 2,
'title': u'Learn Python',
'description': u'Need to find a good Python tutorial on the web',
'done': False
}
]
@app.route('/todo/api/v1.0/tasks', methods=['GET'])
def get_tasks():
return jsonify({'tasks': tasks})
if __name__ == '__main__':
app.run(debug=True)在浏览器上的结果显示如下:

这样就调用了一个RESTful service方法!
现在,我们写第二个版本的GET方法获取特定的任务,获取单个任务:
from flask import abort
@app.route('/todo/api/v1.0/tasks/<int:task_id>', methods=['GET'])
def get_task(task_id):
#检查tasks内部的元素,是否有元素的id值和参数相匹配
task = list(filter(lambda t: t['id'] == task_id, tasks))
#有的话,就返回列表形式包裹的这个元素,没有的话就报错404
if len(task) == 0:
abort(404)
return jsonify({'task': task[0]})
#否则,将这个task以json的格式返回。POST方法添加信息。接下来,既然有数据,那肯定会涉及到添加数据,那我们就要用到POST方法了,就和上传FORM表单的性质是一样的
from flask import request
@app.route('/todo/api/v1.0/tasks', methods=['POST'])
def create_task():
#如果请求里面没有json数据,或者json数据里面title的内容为空
if not request.json or not 'title' in request.json:
abort(400) #返回404错误
task = {
'id': tasks[-1]['id'] + 1, #取末尾tasks的id号+1
'title': request.json['title'], #title必须设置,不能为空。
'description': request.json.get('description', ""),
'done': False
}
tasks.append(task) #完了之后,添加这个task进tasks列表
return jsonify({'task': task}), 201 #并且返回这个添加的task内容和状态码。PUT方法修改和DELETE方法删除。既然已经有了添加的功能,那么修改和删除的也必不可少,如下
@app.route('/todo/api/v1.0/tasks/<int:task_id>', methods=['PUT'])
def update_task(task_id):
#检查是否有这个id数据
task = filter(lambda t: t['id'] == task_id, tasks)
if len(task) == 0:
abort(404)
#如果请求中没有附带json数据,则报错400
if not request.json:
abort(400)
#如果title对应的值,不是字符串类型,则报错400
if 'title' in request.json and type(request.json['title']) != unicode:
abort(400)
if 'description' in request.json and type(request.json['description']) is not unicode:
abort(400)
#检查done对应的值是否是布尔值
if 'done' in request.json and type(request.json['done']) is not bool:
abort(400)
#如果上述条件全部通过的话,更新title的值,同时设置默认值
task[0]['title'] = request.json.get('title', task[0]['title'])
task[0]['description'] = request.json.get('description', task[0]['description'])
task[0]['done'] = request.json.get('done', task[0]['done'])
#返回修改后的数据
return jsonify({'task': task[0]})
@app.route('/todo/api/v1.0/tasks/<int:task_id>', methods=['DELETE'])
def delete_task(task_id):
#检查是否有这个数据
task = filter(lambda t: t['id'] == task_id, tasks)
if len(task) == 0:
abort(404)
#从tasks列表中删除这个值
tasks.remove(task[0])
#返回结果状态,自定义的result
return jsonify({'result': True})优化接口这样做接口系统。让服务可以自动生成URL,所以,这里我们需要写一个辅助函数,来返回一个完整的URL,这样可以就可以直接拿着URL用了。
#添加一个辅助函数
def make_public_task(task):
new_task={} #新建一个对象,字典类型
for key in task: #遍历字典内部的KEY
if key == 'id': #当遍历到id的时候,为新对象增加uri的key,对应的值为完整的uri
new_task['uri'] = url_for('get_task',task_id=task['id'],_external=True)
else:
new_task[key] = task[key] #其他的key,分别一一对应加入新对象
return new_task #最后返回新对象数据
#修改获取合集的路由
@app.route('/todo/api/v1.0/tasks',methods=['GET'])
def get_tasks():
return jsonify({'tasks': list(map(make_public_task,tasks))}) #使用map函数,罗列出所有的数据,返回的数据信息,是经过辅助函数处理的 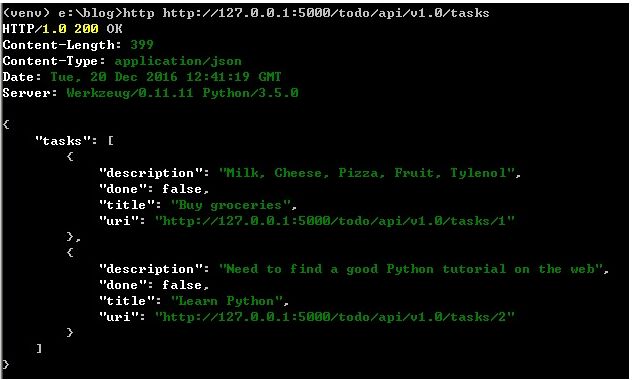
自己没有成功安装curl,网上的截图
总结:这里的web service应该使用真正的数据库,而不是使用内存数据结构,因为限制过多。这两天的时间仅仅是明白一个web大概的过程,后面还有很多东西要学习的,继续加油。
知识巩固
- python字典结构:
ab = { 'liu' :'liu@python.info',
'Larry' : 'larry@wall.org',
'Matsumoto' : 'matz@ruby-lang.org',
'Spammer' : 'spammer@hotmail.com'
}- json数据形式:
{
"clusterInfo":
{
"id":1324053971963,
"startedOn":1324053971963,
"state":"STARTED",
"resourceManagerVersion":"0.23.1-SNAPSHOT",
"resourceManagerVersionBuiltOn":"Tue Dec 13 22:12:48 CST 2011",
"hadoopVersion":"0.23.1-SNAPSHOT",
"hadoopVersionBuiltOn":"Tue Dec 13 22:12:26 CST 2011"
}
}我们会发现,从形式来讲,这两者的确很像,都为 key : value 的形式,那么它们两者的异同是什么呢? 简单来说,python 字典的数据格式就json的数据格式。 但本质上来讲,字典是一种数据结构,json是一种格式;字典有很多内置函数,有多种调用方法,而json是数据打包的一种格式,并不像字典具备操作性,并且是格式就会有一些形式上的限制,比如json的格式要求必须且只能使用双引号作为key或者值的边界符号,不能使用单引号,而且“key”必须使用边界符(双引号),但字典就无所谓了。
- python中json.loads,dumps,jsonify使用
search_info = {'id':132,'user_role':3}
print type(search_info) #输出 <type 'dict'>
#转为string用dumps
print type(json.dumps(search_info)) #输出 <type 'str'>
#string转 dict用 loads()
print type(json.loads(json.dumps(search_info))) #输出 <type 'dict'>如果前后台通过接口交互时,返回给前台json格式数据时可以使用jsonify
#返回给前台json格式数据
return jsonify({'id':132,'user_role':3})如果前台调用A后台接口,A后台接口调用B后台接口,则A后台接口得到B后台的数据返回给前台时,用如下方法:
r = requests.get(www.xxx.com/restful, params={'user_id':1})
#返回的字符串数据先转为dict,再通过json格式传给前台
return jsonify(json.loads(r.text))参考资料:
1.如何理解Python装饰器
3.使用python的Flask实现一个RESTful API服务器端[翻译]