1、内存管理介绍
内存管理的目的是合理分配内存,减少内存碎片,及时回收资源,提高内存的使用资源。
可以带着以下问题进行研究:
- 内存池管理算法是如何实现高效内存分配释放,减少内存碎片?
- 高负载下内存池不断申请/释放,如何实现弹性伸缩?
- 内存池作为全局数据,在多线程环境下如何减少锁竞争?
常见的一些算法有slab,buddy,jemalloc等经典算法。
Netty中的内存管理应该是借鉴了FreeBSD内存管理的思想——jemalloc。Netty内存分配过程中总体遵循以下规则:
- 优先从缓存中分配
- 如果缓存中没有的话,从内存池看看有没有剩余可用的
- 如果已申请的没有的话,再真正申请内存
- 分段管理,每个内存大小范围使用不同的分配策略
2、分配算法
jemalloc依赖多个Arena来分配内存,运行中的应用都有固定数量的多个Arena,默认的数量与处理器的个数相关。系统中多个Arena的原因是由于各个线程进行内存分配时竞争不可避免,Netty允许使用者创建多个分配器来分离锁,提高内存分配效率。
内存分配的调用堆栈看内存分配的主要过程:
- new一个ByteBuf,如果是direct则new:PooledUnsafeDirectByteBuf
- 从缓存中查找,没有可用的缓存进行下一步
- 从内存池中查找可用的内存,查找的方式如上所述(tiny、small、normal)
- 如果找不到则重新申请内存,并将申请到的内存放入内存池
- 使用申请到的内存初始化ByteBuf
线程首次分配/回收内存时,首先会为其分配一个固定的Arena。线程选择Arena时使用round-robin的方式,也就是顺序轮流选取。
各个线程保存各种Arena和缓冲池信息,这样可以减少竞争并提高访问效率。
Arena将内存分为很多Chunk进行管理,Chunk内存保存Page,以页为单位申请。
申请内存分配时,会将分配到的规格分为几类:TINY,SMAILL,NORMAL和HUGE,分别对应不同的范围,处理过程也不相同。
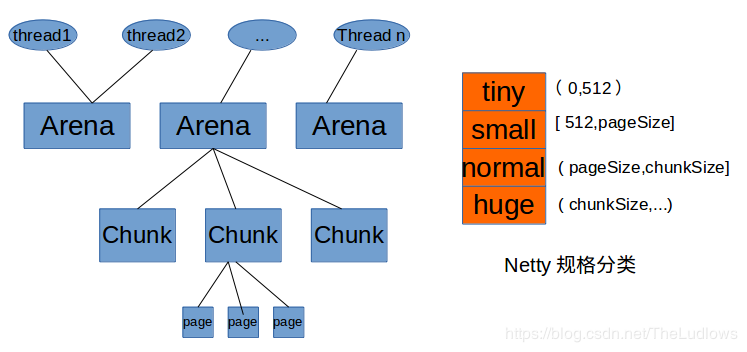
- 内存分配的最小单位为16B。
- 小于512B的请求为Tiny,小于8KB(PageSize)的请求为Small,小于等于16MB(Chunk Size)的请求为Normal,大于16MB(Chun kSize)的请求为Huge。
- 小于512B的请求以16B为起点每次增加16B;大于等于512B的请求则每次加倍。
为了分配内存块保存连续和减少内存碎片,因此Jemalloc使用Buddy内存分配算法。
其实使用二叉树进行管理,树中每个叶子节点表示一个Page,即树高为12。具有相同父节点的叶子节点称为buddy关系,buddy之间自底向上链接为二叉树,直到根节点。
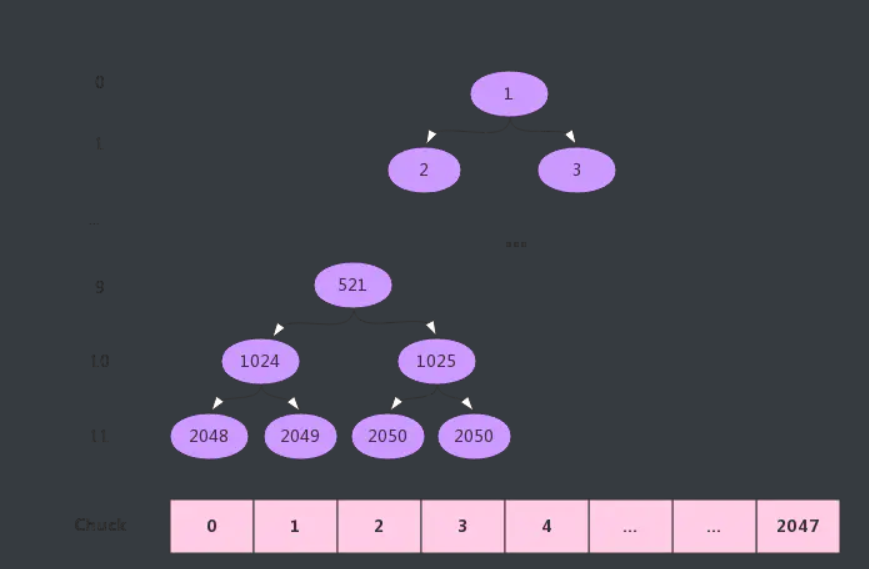
举个例子:8KB、16KB、8KB为例分析分配过程(每个Page大小8KB):
- 8KB:需要一个Page,第11层满足要求,故分配2048节点即Page0;
- 16KB:需要两个Page,故需要在第10层进行分配,而1024的子节点2048已分配,从左到右找到满足要求的1025节点,故分配节点1025即Page2和Page3;
- 8KB:需要一个Page,第11层满足要求,2048已分配,从左到右找到2049节点即Page1进行分配。
分配结束后,已分配连续的Page0-Page3,这样的连续内存块,大大减少内部碎片并提高内存使用率
ByteBuf分类
Netty使用ByteBuf对象作为数据容器,进行I/O读写操作,Netty的内存管理也是围绕着ByteBuf对象高效地分配和释放
当讨论ByteBuf对象管理,主要从以下方面进行分类:
Pooled 和 Unpooled
- 池化内存分配时基于预分配的一整块大内存,取其中的部分封装成ByteBuf提供使用,用完后回收到内存池中。
- 非池化内存每次分配时直接调用系统 API 向操作系统申请ByteBuf需要的同样大小内存,用完后通过系统调用进行释放Pooled。
tips: Netty4默认使用Pooled的方式,可通过参数-Dio.netty.allocator.type=unpooled或pooled进行设置
Heap 和 Direct
- Heap,指ByteBuf关联的内存JVM堆内分配,分配的内存受GC 管理
- Direct,指ByteBuf关联的内存在JVM堆外分配,分配的内存不受GC管理,需要通过系统调用实现申请和释放,底层基于Java NIO的DirectByteBuffer对象
申请/释放内存
当申请分配内存,会首先将请求分配的内存大小归一化(向上取值),通过PoolArena#normalizeCapacity()方法,取最近的2的幂的值,例如8000byte归一化为8192byte( chunkSize/2^11 ),8193byte归一化为16384byte(chunkSize/2^10)
处理内存申请的算法在PoolChunk#allocateRun方法中,当分配已归一化处理后大小为chunkSize/2^d的内存,即需要在depth = d的层级中找到第一块空闲内存,算法从根节点开始遍历 (根节点depth = 0, id = 1),具体步骤如下:
- 步骤1 判断是否当前节点值memoryMap[id] > d,如果是,则无法从该chunk分配内存,查找结束。
- 步骤2 判断是否节点值memoryMap[id] == d,且depth_of_id == h
。如果是,当前节点是depth = d的空闲内存,查找结束,更新当前节点值为memoryMap[id] = max_order + 1,代表节点已使用,并遍历当前节点的所有祖先节点,更新节点值为各自的左右子节点值的最小值;如果否,执行步骤3 - 步骤3 判断是否当前节点值memoryMap[id] <= d,且depth_of_id < h。如果是,则空闲节点在当前节点的子节点中,则先判断左子节点memoryMap[2 * id] <=d(判断左子节点是否可分配),如果成立,则当前节点更新为左子节点,否则更新为右子节点,然后重复步骤2。
释放内存
释放内存时,根据申请内存返回的id,将 memoryMap[id]更新为depth_of_id,同时设置id节点的祖先节点值为各自左右节点的最小值。
巨型对象内存管理
对于申请分配大小超过chunkSize的巨型对象(huge),Netty采用的是非池化管理策略,在每次请求分配内存时单独创建特殊的非池化PoolChunk对象进行管理,内部memoryMap为null,当对象内存释放时整个Chunk内存释放,相应内存申请逻辑在PoolArena#allocateHuge()方法中,释放逻辑在PoolArena#destroyChunk()方法中。
小对象内存管理
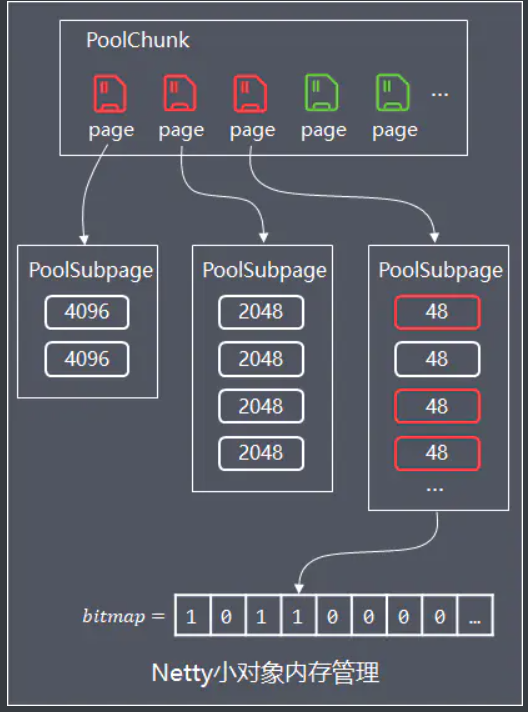
这些小对象直接分配一个page会造成浪费,在page中进行平衡树的标记又额外消耗更多空间,因此Netty的实现是:先PoolChunk中申请空闲page,同一个page分为相同大小规格的小内存进行存储。
弹性伸缩
PoolChunk管理
为了解决单个PoolChunk容量有限的问题,Netty将多个PoolChunk组成链表一起管理,然后用PoolChunkList对象持有链表的head
将所有PoolChunk组成一个链表的话,进行遍历查找管理效率较低,因此Netty设计了PoolArena对象(arena中文是舞台、场所),实现对多个PoolChunkList、PoolSubpage的管理,线程安全控制、对外提供内存分配、释放的服务。
PoolSubpage管理
PoolArena内部持有2个PoolSubpage数组,分别存储tiny和small规格类型的PoolSubpage
并发设计
为了减少线程间的竞争,Netty会提前创建多个PoolArena(默认生成数量 = 2 * CPU核心数),当线程首次请求池化内存分配,会找被最少线程持有的PoolArena,并保存线程局部变量PoolThreadCache中,实现线程与PoolArena的关联绑定(PoolThreadLocalCache#initialValue()方法)。
Netty设计了ThreadLocal的更高性能替代类:FastThreadLocal,需要配套继承Thread的类FastThreadLocalThread一起使用,基本原理是将原来Thead的基于ThreadLocalMap存储局部变量,扩展为能更快速访问的数组进行存储(Object[] indexedVariables),每个FastThreadLocal内部维护了一个全局原子自增的int类型的数组index。
Netty还设计了缓存机制提升并发性能:当请求对象内存释放,PoolArena并没有马上释放,而是先尝试将该内存关联的PoolChunk和chunk中的偏移位置(handler变量)等信息存入PoolThreadLocalCache中的固定大小缓存队列中(如果缓存队列满了则马上释放内存);当请求内存分配,PoolArena会优先访问PoolThreadLocalCache的缓存队列中是否有缓存内存可用,如果有,则直接分配,提高分配效率。
[…] netty内存管理 […]