【架构】异地多活分布式系统架构设计原理
作者:Bogon
链接:https://www.jianshu.com/p/2a1299698da0
在软件开发领域,「异地多活」是分布式系统架构设计的一座高峰,很多人经常听过它,但很少人理解其中的原理。
异地多活到底是什么?
为什么需要异地多活?
它到底解决了什么问题?
究竟是怎么解决的?
这些疑问,想必是每个程序员看到异地多活这个名词时,都想要搞明白的问题。
有幸,我曾经深度参与过一个中等互联网公司,建设异地多活系统的设计与实施过程。
今天,我就来和你聊一聊异地多活背后的的实现原理。
认真读完这篇文章,我相信你会对异地多活架构,有更加深刻的理解。
这篇文章干货很多,希望你可以耐心读完。
01 系统可用性
要想理解异地多活,我们需要从架构设计的原则说起。
现如今,我们开发一个软件系统,对其要求越来越高,如果你了解一些「架构设计」的要求,就知道一个好的软件架构应该遵循以下 3 个原则:
1. 高性能
2. 高可用
3. 易扩展
其中,高性能意味着系统拥有更大流量的处理能力,更低的响应延迟。例如 1 秒可处理 10W 并发请求,接口响应时间 5 ms 等等。
易扩展表示系统在迭代新功能时,能以最小的代价去扩展,系统遇到流量压力时,可以在不改动代码的前提下,去扩容系统。
「高可用」这个概念,看起来很抽象,怎么理解它呢?通常用 2 个指标来衡量:
平均故障间隔 MTBF(Mean Time Between Failure):表示两次故障的间隔时间,也就是系统「正常运行」的平均时间,这个时间越长,说明系统稳定性越高
故障恢复时间 MTTR(Mean Time To Repair):表示系统发生故障后「恢复的时间」,这个值越小,故障对用户的影响越小
可用性与这两者的关系:
可用性(Availability)= MTBF / (MTBF + MTTR) * 100%
这个公式得出的结果是一个「比例」,通常我们会用「N 个 9」来描述一个系统的可用性。
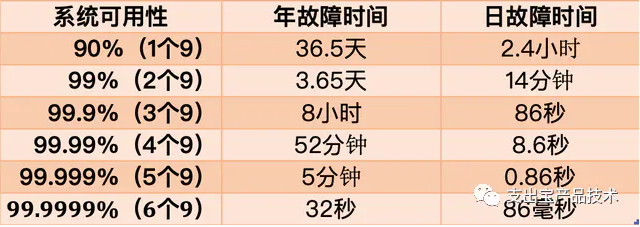
从这张图你可以看到,要想达到 4 个 9 以上的可用性,平均每天故障时间必须控制在 10 秒以内。
也就是说,只有故障的时间「越短」,整个系统的可用性才会越高,每提升 1 个 9,都会对系统提出更高的要求。
我们都知道,系统发生故障其实是不可避免的,尤其是规模越大的系统,发生问题的概率也越大。
这些故障一般体现在 3 个方面:
硬件故障:CPU、内存、磁盘、网卡、交换机、路由器
软件问题:代码 Bug、版本迭代
不可抗力:地震、水灾、火灾、战争
这些风险随时都有可能发生。所以,在面对故障时,我们的系统能否以「最快」的速度恢复,就成为了可用性的关键。
可如何做到快速恢复呢?
这篇文章要讲的「异地多活」架构,就是为了解决这个问题,而提出的高效解决方案。
下面,我会从一个最简单的系统出发,带你一步步演化出一个支持「异地多活」的系统架构。
在这个过程中,你会看到一个系统会遇到哪些可用性问题,以及为什么架构要这样演进,从而理解异地多活架构的意义。
02 单机架构
我们从最简单的开始讲起。
假设你的业务处于起步阶段,体量非常小,那你的架构是这样的:
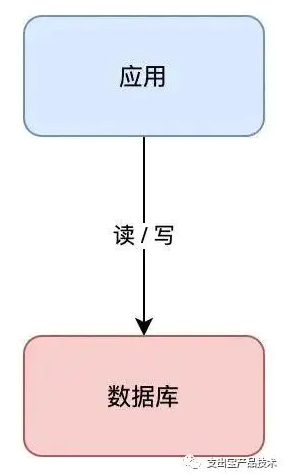
这个架构模型非常简单,客户端请求进来,业务应用读写数据库,返回结果,非常好理解。
但需要注意的是,这里的数据库是「单机」部署的,所以它有一个致命的缺点:一旦遭遇意外,例如磁盘损坏、操作系统异常、误删数据,那这意味着所有数据就全部「丢失」了,这个损失是巨大的。
如何避免这个问题呢?我们很容易想到一个方案:备份。
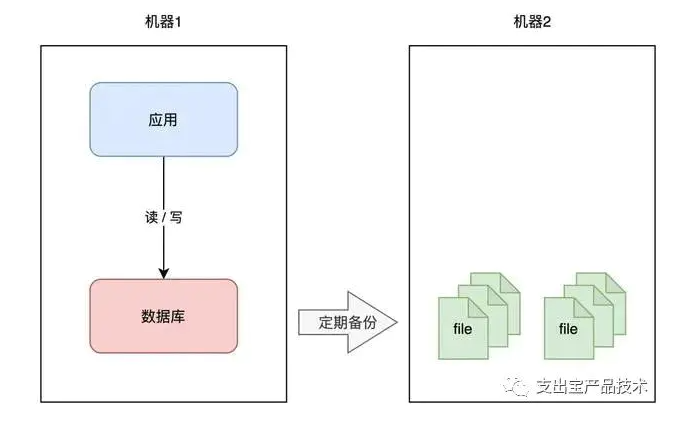
你可以对数据做备份,把数据库文件「定期」cp 到另一台机器上,这样,即使原机器丢失数据,你依旧可以通过备份把数据「恢复」回来,以此保证数据安全。
这个方案实施起来虽然比较简单,但存在 2 个问题:
恢复需要时间:业务需先停机,再恢复数据,停机时间取决于恢复的速度,恢复期间服务「不可用」
数据不完整:因为是定期备份,数据肯定不是「最新」的,数据完整程度取决于备份的周期
很明显,你的数据库越大,意味故障恢复时间越久。那按照前面我们提到的「高可用」标准,这个方案可能连 1 个 9 都达不到,远远无法满足我们对可用性的要求。
那有什么更好的方案,既可以快速恢复业务?还能尽可能保证数据完整性呢?
这时你可以采用这个方案:主从副本。
03 主从副本
你可以在另一台机器上,再部署一个数据库实例,让这个新实例成为原实例的「副本」,让两者保持「实时同步」,就像这样:
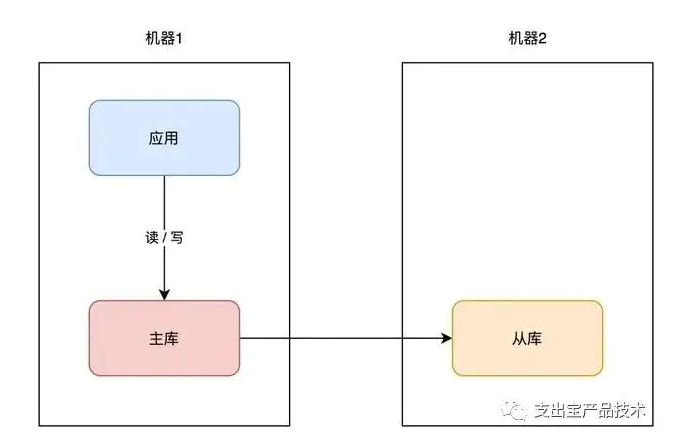
我们一般把原实例叫作主库(master),新实例叫作从库(slave)。这个方案的优点在于:
数据完整性高:主从副本实时同步,数据「差异」很小
抗故障能力提升:主库有任何异常,从库可随时「切换」为主库,继续提供服务
读性能提升:业务应用可直接读从库,分担主库「压力」读压力
这个方案不错,不仅大大提高了数据库的可用性,还提升了系统的读性能。
同样的思路,你的「业务应用」也可以在其它机器部署一份,避免单点。因为业务应用通常是「无状态」的(不像数据库那样存储数据),所以直接部署即可,非常简单。
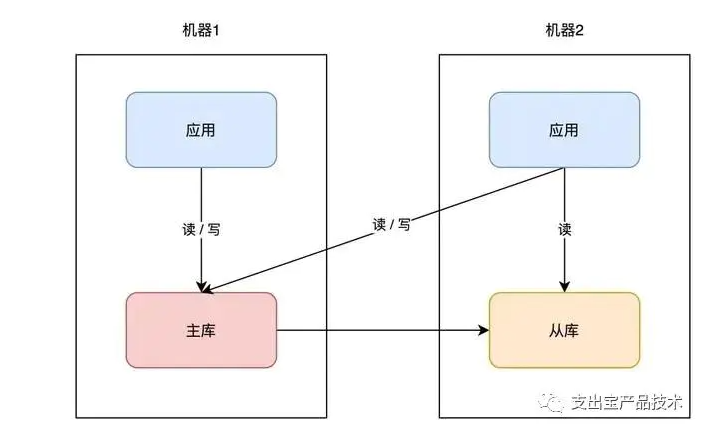
因为业务应用部署了多个,所以你现在还需要部署一个「接入层」,来做请求的「负载均衡」(一般会使用 nginx 或 LVS),这样当一台机器宕机后,另一台机器也可以「接管」所有流量,持续提供服务。
从这个方案你可以看出,提升可用性的关键思路就是:冗余。
没错,担心一个实例故障,那就部署多个实例,担心一个机器宕机,那就部署多台机器。
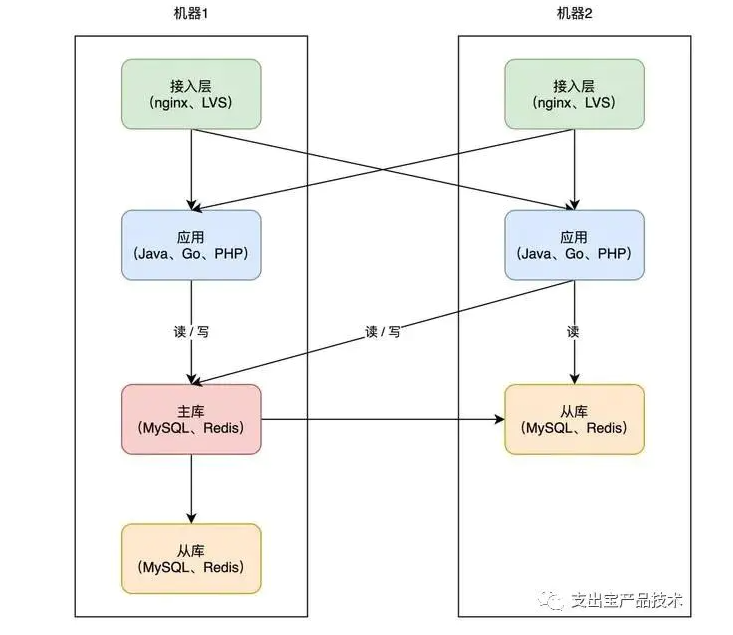
到这里,你的架构基本已演变成主流方案了,之后开发新的业务应用,都可以按照这种模式去部署。
但这种方案还有什么风险吗?
04 风险不可控
现在让我们把视角下放,把焦点放到具体的「部署细节」上来。
按照前面的分析,为了避免单点故障,你的应用虽然部署了多台机器,但这些机器的分布情况,我们并没有去深究。
而一个机房有很多服务器,这些服务器通常会分布在一个个「机柜」上,如果你使用的这些机器,刚好在一个机柜,还是存在风险。
如果恰好连接这个机柜的交换机 / 路由器发生故障,那么你的应用依旧有「不可用」的风险。
虽然交换机 / 路由器也做了路线冗余,但不能保证一定不出问题。
部署在一个机柜有风险,那把这些机器打散,分散到不同机柜上,是不是就没问题了?
这样确实会大大降低出问题的概率。但我们依旧不能掉以轻心,因为无论怎么分散,它们总归还是在一个相同的环境下:机房。
那继续追问,机房会不会发生故障呢?
一般来讲,建设一个机房的要求其实是很高的,地理位置、温湿度控制、备用电源等等,机房厂商会在各方面做好防护。但即使这样,我们每隔一段时间还会看到这样的新闻:
2015 年 5 月 27 日,杭州市某地光纤被挖断,近 3 亿用户长达 5 小时无法访问支付宝
2021 年 7 月 13 日,B 站部分服务器机房发生故障,造成整站持续 3 个小时无法访问
2021 年 10 月 9 日,富途证券服务器机房发生电力闪断故障,造成用户 2 个小时无法登陆、交易
...
可见,即使机房级别的防护已经做得足够好,但只要有「概率」出问题,那现实情况就有可能发生。虽然概率很小,但一旦真的发生,影响之大可见一斑。
看到这里你可能会想,机房出现问题的概率也太小了吧,工作了这么多年,也没让我碰上一次,有必要考虑得这么复杂吗?
但你有没有思考这样一个问题:不同体量的系统,它们各自关注的重点是什么?
体量很小的系统,它会重点关注「用户」规模、增长,这个阶段获取用户是一切。
**等用户体量上来了,这个阶段会重点关注「性能」,优化接口响应时间、页面打开速度等等,这个阶段更多是关注用户体验。
**
等体量再大到一定规模后你会发现,「可用性」就变得尤为重要。像微信、支付宝这种全民级的应用,如果机房发生一次故障,那整个影响范围可以说是非常巨大的。
所以,再小概率的风险,我们在提高系统可用性时,也不能忽视。
分析了风险,再说回我们的架构。那到底该怎么应对机房级别的故障呢?
没错,还是冗余。
05 同城灾备
**想要抵御「机房」级别的风险,那应对方案就不能局限在一个机房内了。
**
现在,你需要做机房级别的冗余方案,也就是说,你需要再搭建一个机房,来部署你的服务。
简单起见,你可以在「同一个城市」再搭建一个机房,原机房我们叫作 A 机房,新机房叫 B 机房,这两个机房的网络用一条「专线」连通。
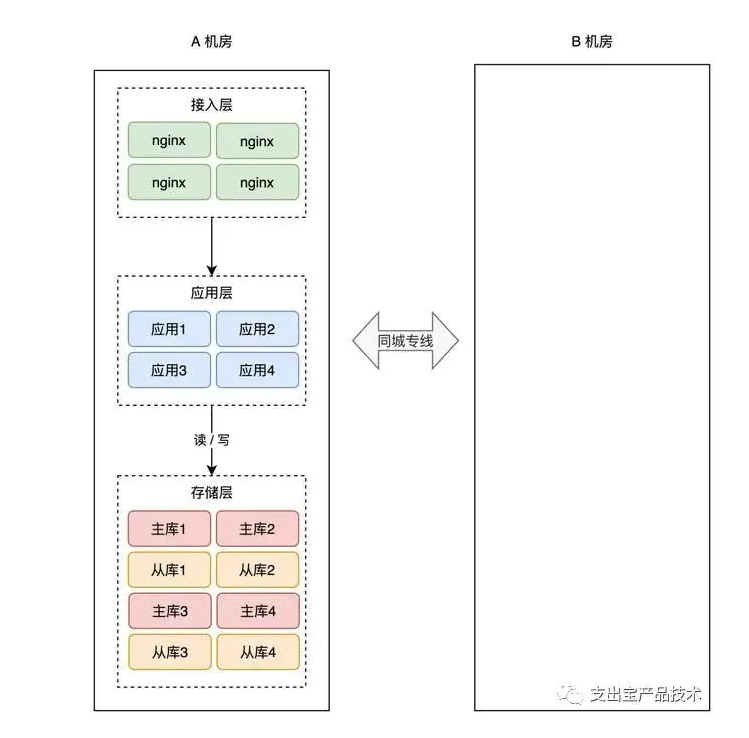
有了新机房,怎么把它用起来呢?这里还是要优先考虑「数据」风险。
为了避免 A 机房故障导致数据丢失,所以我们需要把数据在 B 机房也存一份。最简单的方案还是和前面提到的一样:备份。
A 机房的数据,定时在 B 机房做备份(拷贝数据文件),这样即使整个 A 机房遭到严重的损坏,B 机房的数据不会丢,通过备份可以把数据「恢复」回来,重启服务。
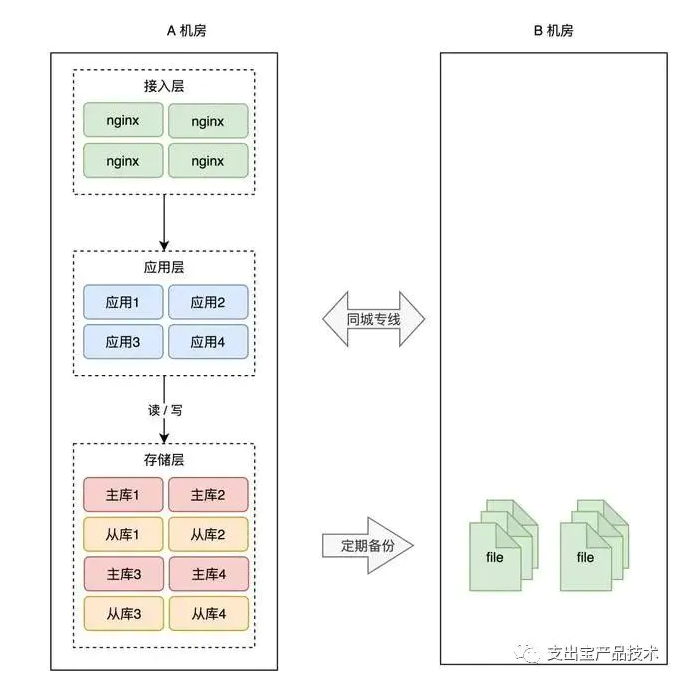
这种方案,我们称之为「冷备」。为什么叫冷备呢?因为 B 机房只做备份,不提供实时服务,它是冷的,只会在 A 机房故障时才会启用。
但备份的问题依旧和之前描述的一样:数据不完整、恢复数据期间业务不可用,整个系统的可用性还是无法得到保证。
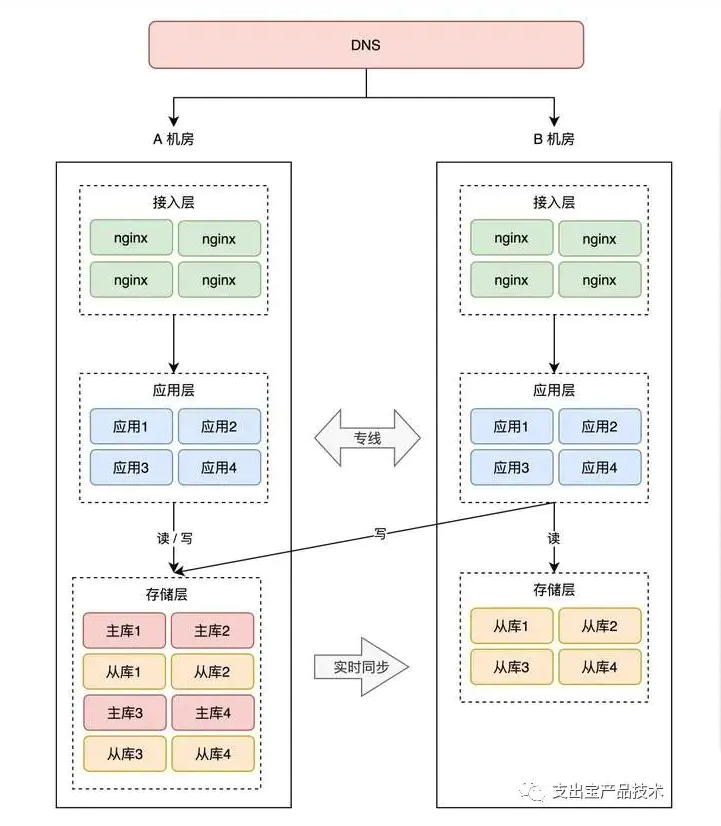
所以,我们还是需要用「主从副本」的方式,在 B 机房部署 A 机房的数据副本,架构就变成了这样:
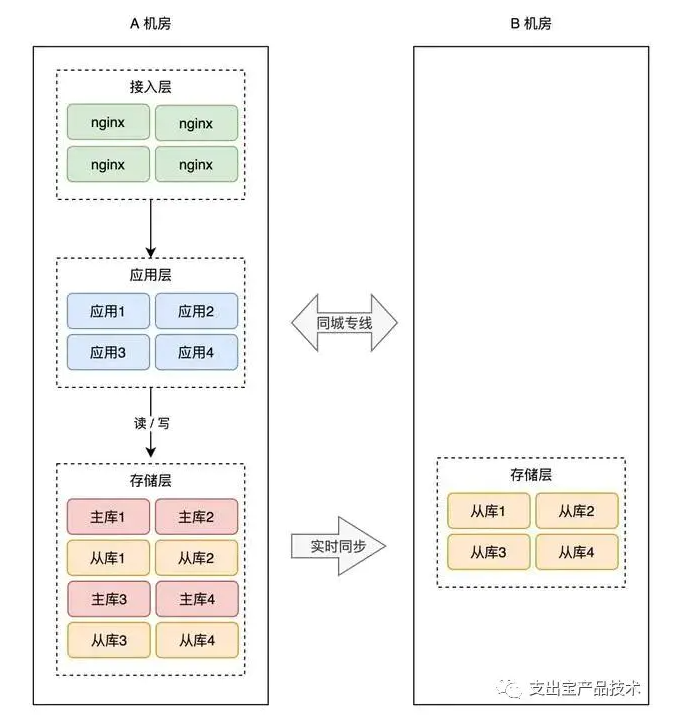
这样,就算整个 A 机房挂掉,我们在 B 机房也有比较「完整」的数据。
数据是保住了,但这时你需要考虑另外一个问题:如果 A 机房真挂掉了,要想保证服务不中断,你还需要在 B 机房「紧急」做这些事情:
1. B 机房所有从库提升为主库
2. 在 B 机房部署应用,启动服务
3. 部署接入层,配置转发规则
4. DNS 指向 B 机房,接入流量,业务恢复
看到了么?A 机房故障后,B 机房需要做这么多工作,你的业务才能完全「恢复」过来。
你看,整个过程需要人为介入,且需花费大量时间来操作,恢复之前整个服务还是不可用的,这个方案还是不太爽,如果能做到故障后立即「切换」,那就好了。
因此,要想缩短业务恢复的时间,你必须把这些工作在 B 机房「提前」做好,也就是说,你需要在 B 机房提前部署好接入层、业务应用,等待随时切换。
架构就变成了这样:
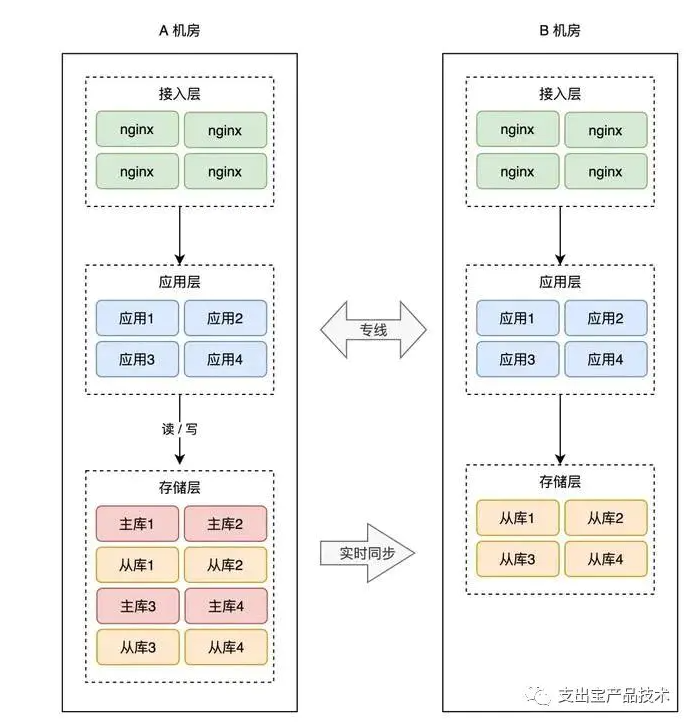
这样的话,A 机房整个挂掉,我们只需要做 2 件事即可:
1. B 机房所有从库提升为主库
2. DNS 指向 B 机房,接入流量,业务恢复
这样一来,恢复速度快了很多。
到这里你会发现,B 机房从最开始的「空空如也」,演变到现在,几乎是「镜像」了一份 A 机房的所有东西,从最上层的接入层,到中间的业务应用,到最下层的存储。
两个机房唯一的区别是,A 机房的存储都是主库,而 B 机房都是从库。
这种方案,我们把它叫做「热备」。
热的意思是指,B 机房处于「待命」状态,A 故障后 B 可以随时「接管」流量,继续提供服务。热备相比于冷备最大的优点是:随时可切换。
无论是冷备还是热备,因为它们都处于「备用」状态,所以我们把这两个方案统称为:同城灾备。
同城灾备的最大优势在于,我们再也不用担心「机房」级别的故障了,一个机房发生风险,我们只需把流量切换到另一个机房即可,可用性再次提高,是不是很爽?(后面还有更爽的)
06 同城双活
我们继续来看这个架构。
虽然我们有了应对机房故障的解决方案,但这里有个问题是我们不能忽视的:A 机房挂掉,全部流量切到 B 机房,B 机房能否真的如我们所愿,正常提供服务?
这是个值得思考的问题。
这就好比有两支军队 A 和 B,A 军队历经沙场,作战经验丰富,而 B 军队只是后备军,除了有军人的基本素养之外,并没有实战经验,战斗经验基本为 0。
如果 A 军队丧失战斗能力,需要 B 军队立即顶上时,作为指挥官的你,肯定也会担心 B 军队能否真的担此重任吧?
我们的架构也是如此,此时的 B 机房虽然是随时「待命」状态,但 A 机房真的发生故障,我们要把全部流量切到 B 机房,其实是不敢百分百保证它可以「如期」工作的。
你想,我们在一个机房内部署服务,还总是发生各种各样的问题,例如:发布应用的版本不一致、系统资源不足、操作系统参数不一样等等。现在多部署一个机房,这些问题只会增多,不会减少。
另外,从「成本」的角度来看,我们新部署一个机房,需要购买服务器、内存、硬盘、带宽资源,花费成本也是非常高昂的,只让它当一个后备军,未免也太「大材小用」了!
因此,我们需要让 B 机房也接入流量,实时提供服务,这样做的好处,一是可以实时训练这支后备军,让它达到与 A 机房相同的作战水平,随时可切换,二是 B 机房接入流量后,可以分担 A 机房的流量压力。这才是把 B 机房资源优势,发挥最大化的最好方案!
那怎么让 B 机房也接入流量呢?很简单,就是把 B 机房的接入层 IP 地址,加入到 DNS 中,这样,B 机房从上层就可以有流量进来了。

但这里有一个问题:别忘了,B 机房的存储,现在可都是 A 机房的「从库」,从库默认可都是「不可写」的,B 机房的写请求打到本机房存储上,肯定会报错,这还是不符合我们预期。怎么办?
这时,你就需要在「业务应用」层做改造了。
你的业务应用在操作数据库时,需要区分「读写分离」(一般用中间件实现),即两个机房的「读」流量,可以读任意机房的存储,但「写」流量,只允许写 A 机房,因为主库在 A 机房。
这会涉及到你用的所有存储,例如项目中用到了 MySQL、Redis、MongoDB 等等,操作这些数据库,都需要区分读写请求,所以这块需要一定的业务「改造」成本。
因为 A 机房的存储都是主库,所以我们把 A 机房叫做「主机房」,B 机房叫「从机房」。
两个机房部署在「同城」,物理距离比较近,而且两个机房用「专线」网络连接,虽然跨机房访问的延迟,比单个机房内要大一些,但整体的延迟还是可以接受的。
业务改造完成后,B 机房可以慢慢接入流量,从 10%、30%、50% 逐渐覆盖到 100%,你可以持续观察 B 机房的业务是否存在问题,有问题及时修复,逐渐让 B 机房的工作能力,达到和 A 机房相同水平。
现在,因为 B 机房实时接入了流量,此时如果 A 机房挂了,那我们就可以「大胆」地把 A 的流量,全部切换到 B 机房,完成快速切换!
到这里你可以看到,我们部署的 B 机房,在物理上虽然与 A 有一定距离,但整个系统从「逻辑」上来看,我们是把这两个机房看做一个「整体」来规划的,也就是说,相当于把 2 个机房当作 1 个机房来用。
这种架构方案,比前面的同城灾备更「进了一步」,B 机房实时接入了流量,还能应对随时的故障切换,这种方案我们把它叫做「同城双活」。
因为两个机房都能处理业务请求,这对我们系统的内部维护、改造、升级提供了更多的可实施空间(流量随时切换),现在,整个系统的弹性也变大了,是不是更爽了?
那这种架构有什么问题呢?
07 两地三中心
还是回到风险上来说。
虽然我们把 2 个机房当做一个整体来规划,但这 2 个机房在物理层面上,还是处于「一个城市」内,如果是整个城市发生自然灾害,例如地震、水灾(河南水灾刚过去不久),那 2 个机房依旧存在「全局覆没」的风险。
真是防不胜防啊?怎么办?没办法,继续冗余。
但这次冗余机房,就不能部署在同一个城市了,你需要把它放到距离更远的地方,部署在「异地」。
通常建议两个机房的距离要在 1000 公里以上,这样才能应对城市级别的灾难。
假设之前的 A、B 机房在北京,那这次新部署的 C 机房可以放在上海。
按照前面的思路,把 C 机房用起来,最简单粗暴的方案还就是做「冷备」,即定时把 A、B 机房的数据,在 C 机房做备份,防止数据丢失。
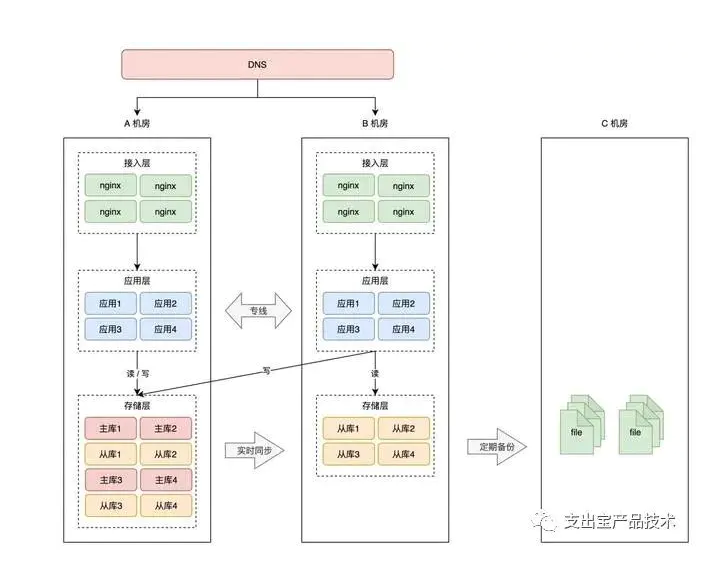
这种方案,就是我们经常听到的「两地三中心」。
两地是指 2 个城市,三中心是指有 3 个机房,其中 2 个机房在同一个城市,并且同时提供服务,第 3 个机房部署在异地,只做数据灾备。
这种架构方案,通常用在银行、金融、政企相关的项目中。
它的问题还是前面所说的,启用灾备机房需要时间,而且启用后的服务,不确定能否如期工作。
所以,要想真正的抵御城市级别的故障,越来越多的互联网公司,开始实施「异地双活」。
08 伪异地双活
这里,我们还是分析 2 个机房的架构情况。
我们不再把 A、B 机房部署在同一个城市,而是分开部署,例如 A 机房放在北京,B 机房放在上海。
前面我们讲了同城双活,那异地双活是不是直接「照搬」同城双活的模式去部署就可以了呢?
事情没你想的那么简单。
如果还是按照同城双活的架构来部署,那异地双活的架构就是这样的:
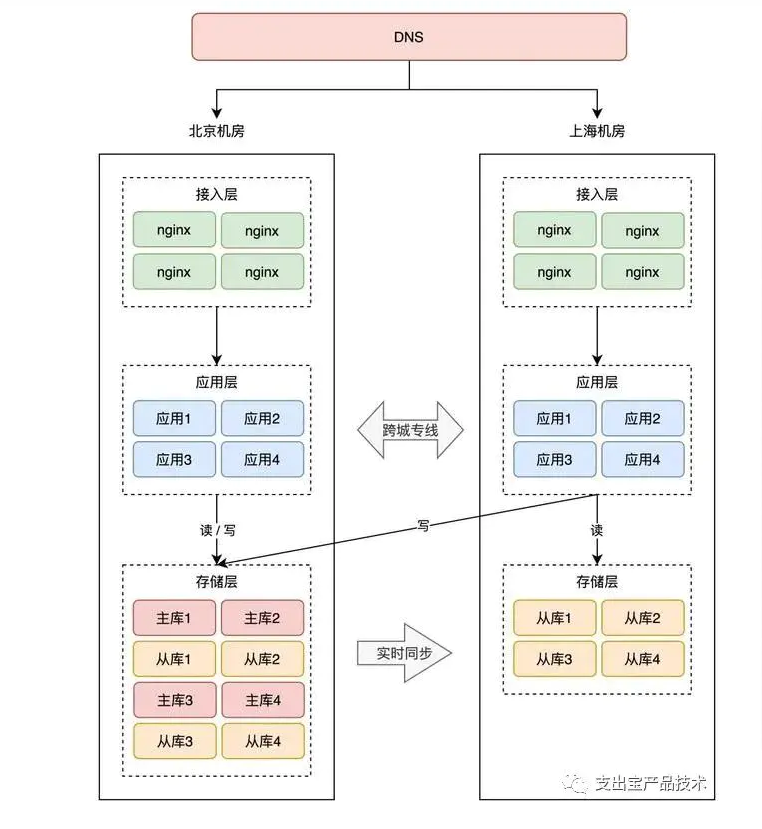
注意看,两个机房的网络是通过「跨城专线」连通的。
此时两个机房都接入流量,那上海机房的请求,可能要去读写北京机房的存储,这里存在一个很大的问题:网络延迟。
因为两个机房距离较远,受到物理距离的限制,现在,两地之间的网络延迟就变成了「不可忽视」的因素了。
北京到上海的距离大约 1300 公里,即使架设一条高速的「网络专线」,光纤以光速传输,一个来回也需要近 10ms 的延迟。
况且,网络线路之间还会经历各种路由器、交换机等网络设备,实际延迟可能会达到 30ms ~ 100ms,如果网络发生抖动,延迟甚至会达到 1 秒。
不止是延迟,远距离的网络专线质量,是远远达不到机房内网络质量的,专线网络经常会发生延迟、丢包、甚至中断的情况。总之,不能过度信任和依赖「跨城专线」。
**你可能会问,这点延迟对业务影响很大吗?影响非常大!
**
试想,一个客户端请求打到上海机房,上海机房要去读写北京机房的存储,一次跨机房访问延迟就达到了 30ms,这大致是机房内网网络(0.5 ms)访问速度的 60 倍(30ms / 0.5ms),一次请求慢 60 倍,来回往返就要慢 100 倍以上。
而我们在 App 打开一个页面,可能会访问后端几十个 API,每次都跨机房访问,整个页面的响应延迟有可能就达到了秒级,这个性能简直惨不忍睹,难以接受。
看到了么,虽然我们只是简单的把机房部署在了「异地」,但「同城双活」的架构模型,在这里就不适用了,还是按照这种方式部署,这是「伪异地双活」!
那如何做到真正的异地双活呢?
09 真正的异地双活
既然「跨机房」调用延迟是不容忽视的因素,那我们只能尽量避免跨机房「调用」,规避这个延迟问题。
也就是说,上海机房的应用,不能再「跨机房」去读写北京机房的存储,只允许读写上海本地的存储,实现「就近访问」,这样才能避免延迟问题。
还是之前提到的问题:上海机房存储都是从库,不允许写入啊,除非我们只允许上海机房接入「读流量」,不接收「写流量」,否则无法满足不再跨机房的要求。
很显然,只让上海机房接收读流量的方案不现实,因为很少有项目是只有读流量,没有写流量的。所以这种方案还是不行,这怎么办?
此时,你就必须在「存储层」做改造了。
要想上海机房读写本机房的存储,那上海机房的存储不能再是北京机房的从库,而是也要变为「主库」。
你没看错,两个机房的存储必须都是「主库」,而且两个机房的数据还要「互相同步」数据,即客户端无论写哪一个机房,都能把这条数据同步到另一个机房。
因为只有两个机房都拥有「全量数据」,才能支持任意切换机房,持续提供服务。
怎么实现这种「双主」架构呢?它们之间如何互相同步数据?
如果你对 MySQL 有所了解,MySQL 本身就提供了双主架构,它支持双向复制数据,但平时用的并不多。而且 Redis、MongoDB 等数据库并没有提供这个功能,所以,你必须开发对应的「数据同步中间件」来实现双向同步的功能。
此外,除了数据库这种有状态的软件之外,你的项目通常还会使用到消息队列,例如 RabbitMQ、Kafka,这些也是有状态的服务,所以它们也需要开发双向同步的中间件,支持任意机房写入数据,同步至另一个机房。
看到了么,这一下子复杂度就上来了,单单针对每个数据库、队列开发同步中间件,就需要投入很大精力了。
**业界也开源出了很多数据同步中间件,例如阿里的 Canal、RedisShake、MongoShake,可分别在两个机房同步 MySQL、Redis、MongoDB 数据。
**
很多有能力的公司,也会采用自研同步中间件的方式来做,例如饿了么、携程、美团都开发了自己的同步中间件。
现在,整个架构就变成了这样:
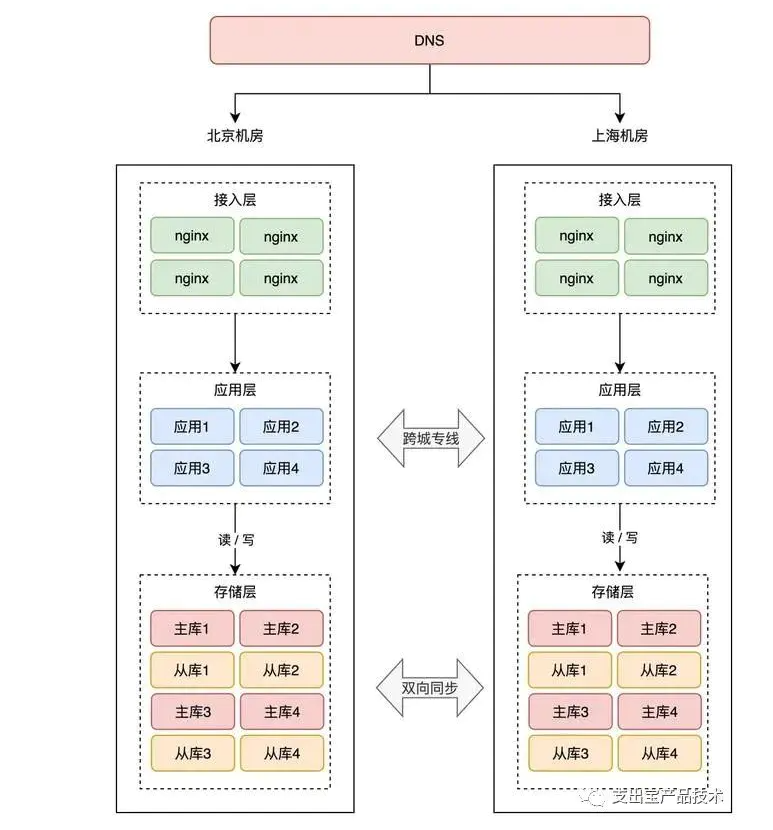
注意看,两个机房的存储层都互相同步数据的。
有了数据同步中间件,就可以达到这样的效果:
北京机房写入 X = 1
上海机房写入 Y = 2
数据通过中间件双向同步
北京、上海机房都有 X = 1、Y = 2 的数据
这里我们用中间件双向同步数据,就不用再担心专线问题,专线出问题,我们的中间件可以自动重试,直到成功,达到数据最终一致。
但这里还会遇到一个问题,两个机房都可以写,操作的不是同一条数据那还好,如果修改的是同一条的数据,发生冲突怎么办?
用户短时间内发了 2 个修改请求,都是修改同一条数据:
一个请求落在北京机房,修改 X = 1(还未同步到上海机房)
另一个请求落在上海机房,修改 X = 2(还未同步到北京机房)
两个机房以哪个为准?
也就是说,在很短的时间内,同一个用户修改同一条数据,两个机房无法确认谁先谁后,数据发生「冲突」。
这是一个很严重的问题,系统发生故障并不可怕,可怕的是数据发生「错误」,因为修正数据的成本太高了。
我们一定要避免这种情况的发生。
解决这个问题,有 2 个方案。
第一个方案,数据同步中间件要有自动「合并」数据、解决「冲突」的能力。
这个方案实现起来比较复杂,要想合并数据,就必须要区分出「先后」顺序。
我们很容易想到的方案,就是以「时间」为标尺,以「后到达」的请求为准。
但这种方案需要两个机房的「时钟」严格保持一致才行,否则很容易出现问题。例如:
第 1 个请求落到北京机房,北京机房时钟是 10:01,修改 X = 1
第 2 个请求落到上海机房,上海机房时钟是 10:00,修改 X = 2
因为北京机房的时间「更晚」,那最终结果就会是 X = 1。但这里其实应该以第 2 个请求为准,X = 2 才对。
可见,完全「依赖」时钟的冲突解决方案,不太严谨。
所以,通常会采用第二种方案,从「源头」就避免数据冲突的发生。
10 如何实施异地双活
既然自动合并数据的方案实现成本高,那我们就要想,能否从源头就「避免」数据冲突呢?
这个思路非常棒!
从源头避免数据冲突的思路是:在最上层接入流量时,就不要让冲突的情况发生。
具体来讲就是,要在最上层就把用户「区分」开,部分用户请求固定打到北京机房,其它用户请求固定打到上海 机房,进入某个机房的用户请求,之后的所有业务操作,都在这一个机房内完成,从根源上避免「跨机房」。
所以这时,你需要在接入层之上,再部署一个「路由层」(通常部署在云服务器上),自己可以配置路由规则,把用户「分流」到不同的机房内。

但这个路由规则,具体怎么定呢?有很多种实现方式,最常见的我总结了 3 类:
按业务类型分片
直接哈希分片
按地理位置分片
1、按业务类型分片
这种方案是指,按应用的「业务类型」来划分。
举例:假设我们一共有 4 个应用,北京和上海机房都部署这些应用。但应用 1、2 只在北京机房接入流量,在上海机房只是热备。应用 3、4 只在上海机房接入流量,在北京机房是热备。
这样一来,应用 1、2 的所有业务请求,只读写北京机房存储,应用 3、4 的所有请求,只会读写上海机房存储。
这样按业务类型分片,也可以避免同一个用户修改同一条数据。

2、直接哈希分片
这种方案就是,最上层的路由层,会根据用户 ID 计算「哈希」取模,然后从路由表中找到对应的机房,之后把请求转发到指定机房内。
举例:一共 200 个用户,根据用户 ID 计算哈希值,然后根据路由规则,把用户 1 - 100 路由到北京机房,101 - 200 用户路由到上海机房,这样,就避免了同一个用户修改同一条数据的情况发生。

3、按地理位置分片
这种方案,非常适合与地理位置密切相关的业务,例如打车、外卖服务就非常适合这种方案。
拿外卖服务举例,你要点外卖肯定是「就近」点餐,整个业务范围相关的有商家、用户、骑手,它们都是在相同的地理位置内的。
针对这种特征,就可以在最上层,按用户的「地理位置」来做分片,分散到不同的机房。
举例:北京、河北地区的用户点餐,请求只会打到北京机房,而上海、浙江地区的用户,请求则只会打到上海机房。这样的分片规则,也能避免数据冲突。


注意:这 3 种常见的分片规则,第一次看不太好理解,建议配合图多理解几遍。搞懂这 3 个分片规则,你才能真正明白怎么做异地多活。
总之,分片的核心思路在于,让同一个用户的相关请求,只在一个机房内完成所有业务「闭环」,不再出现「跨机房」访问。
阿里在实施这种方案时,给它起了个名字,叫做「单元化」。
**当然,最上层的路由层把用户分片后,理论来说同一个用户只会落在同一个机房内,但不排除程序 Bug 导致用户会在两个机房「漂移」。
**
安全起见,每个机房在写存储时,还需要有一套机制,能够检测「数据归属」,应用层操作存储时,需要通过中间件来做「兜底」,避免不该写本机房的情况发生。(篇幅限制,这里不展开讲,理解思路即可)
现在,两个机房就可以都接收「读写」流量(做好分片的请求),底层存储保持「双向」同步,两个机房都拥有全量数据,当任意机房故障时,另一个机房就可以「接管」全部流量,实现快速切换,简直不要太爽。
不仅如此,因为机房部署在异地,我们还可以更细化地「优化」路由规则,让用户访问就近的机房,这样整个系统的性能也会大大提升。
这里还有一种情况,是无法做数据分片的:全局数据。例如系统配置、商品库存这类需要强一致的数据,这类服务依旧只能采用写主机房,读从机房的方案,不做双活。
双活的重点,是要优先保证「核心」业务先实现双活,并不是「全部」业务实现双活。
至此,我们才算实现了真正的「异地双活」!
到这里你可以看出,完成这样一套架构,需要投入的成本是巨大的。
路由规则、路由转发、数据同步中间件、数据校验兜底策略,不仅需要开发强大的中间件,同时还要业务配合改造(业务边界划分、依赖拆分)等一些列工作,没有足够的人力物力,这套架构很难实施。
11 异地多活
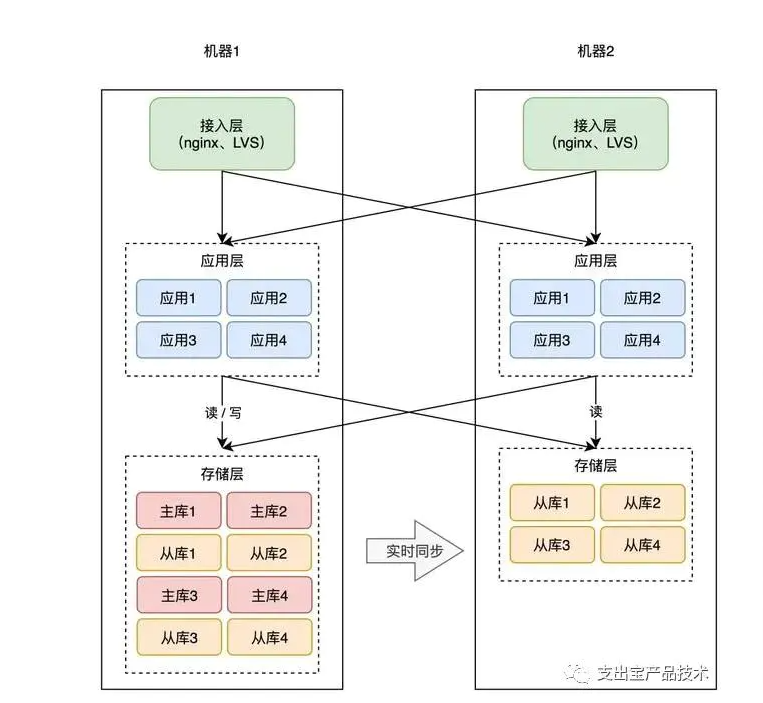
理解了异地双活,那「异地多活」顾名思义,就是在异地双活的基础上,部署多个机房即可。架构变成了这样:

这些服务按照「单元化」的部署方式,可以让每个机房部署在任意地区,随时扩展新机房,你只需要在最上层定义好分片规则就好了。
但这里还有一个小问题,随着扩展的机房越来越多,当一个机房写入数据后,需要同步的机房也越来越多,这个实现复杂度会比较高。
所以业界又把这一架构又做了进一步优化,把「网状」架构升级为「星状」:

这种方案必须设立一个「中心机房」,任意机房写入数据后,都只同步到中心机房,再由中心机房同步至其它机房。
这样做的好处是,一个机房写入数据,只需要同步数据到中心机房即可,不需要再关心一共部署了多少个机房,实现复杂度大大「简化」。
但与此同时,这个中心机房的「稳定性」要求会比较高。不过也还好,即使中心机房发生故障,我们也可以把任意一个机房,提升为中心机房,继续按照之前的架构提供服务。
至此,我们的系统彻底实现了「异地多活」!
多活的优势在于,可以任意扩展机房「就近」部署。任意机房发生故障,可以完成快速「切换」,大大提高了系统的可用性。
同时,我们也再也不用担心系统规模的增长,因为这套架构具有极强的「扩展能力」。
怎么样?
我们从一个最简单的应用,一路优化下来,到最终的架构方案,有没有帮你彻底理解异地多活呢?
12 总结
好了,总结一下这篇文章的重点。
1、一个好的软件架构,应该遵循高性能、高可用、易扩展 3 大原则,其中「高可用」在系统规模变得越来越大时,变得尤为重要
2、系统发生故障并不可怕,能以「最快」的速度恢复,才是高可用追求的目标,异地多活是实现高可用的有效手段
3、提升高可用的核心是「冗余」,备份、主从副本、同城灾备、同城双活、两地三中心、异地双活,异地多活都是在做冗余
4、同城灾备分为「冷备」和「热备」,冷备只备份数据,不提供服务,热备实时同步数据,并做好随时切换的准备
5、同城双活比灾备的优势在于,两个机房都可以接入「读写」流量,提高可用性的同时,还提升了系统性能。虽然物理上是两个机房,但「逻辑」上还是当做一个机房来用
6、两地三中心是在同城双活的基础上,额外部署一个异地机房做「灾备」,用来抵御「城市」级别的灾害,但启用灾备机房需要时间
7、异地双活才是抵御「城市」级别灾害的更好方案,两个机房同时提供服务,故障随时可切换,可用性高。但实现也最复杂,理解了异地双活,才能彻底理解异地多活
8、异地多活是在异地双活的基础上,任意扩展多个机房,不仅又提高了可用性,还能应对更大规模的流量的压力,扩展性最强,是实现高可用的最终方案
13 后记
这篇文章我从「宏观」层面,向你介绍了异地多活架构的「核心」思路,整篇文章的信息量还是很大的,如果不太好理解,我建议你多读几遍。
因为篇幅限制,很多细节我并没有展开来讲。这篇文章更像是讲异地多活的架构之「道」,而真正实施的「术」,要考虑的点其实也非常繁多,因为它需要开发强大的「基础设施」才可以完成实施。
不仅如此,要想真正实现异地多活,还需要遵循一些原则,例如业务梳理、业务分级、数据分类、数据最终一致性保障、机房切换一致性保障、异常处理等等。同时,相关的运维设施、监控体系也要能跟得上才行。
宏观上需要考虑业务(微服务部署、依赖、拆分、SDK、Web 框架)、基础设施(服务发现、流量调度、持续集成、同步中间件、自研存储),微观上要开发各种中间件,还要关注中间件的高性能、高可用、容错能力,其复杂度之高,只有亲身参与过之后才知道。
我曾经有幸参与过,存储层同步中间件的设计与开发,实现过「跨机房」同步 MySQL、Redis、MongoDB 的中间件,踩过的坑也非常多。当然,这些中间件的设计思路也非常有意思,有时间单独分享一下这些中间件的设计思路。
值得提醒你的是,只有真正理解了「异地双活」,才能彻底理解「异地多活」。在我看来,从同城双活演变为异地双活的过程,是最为复杂的,最核心的东西包括,业务单元化划分、存储层数据双向同步、最上层的分片逻辑,这些是实现异地多活的重中之重。
14 参考
饿了么异地多活技术实现(一)总体介绍
https://zhuanlan.zhihu.com/p/32009822
饿了么异地多活技术实现(二)API-Router的设计与实现
https://zhuanlan.zhihu.com/p/32587960
阿里异地多活与同城双活架构
https://www.docin.com/p-2471761270.html
谈谈异地多活架构
https://www.sohu.com/a/315098882_760387
阿里云云原生异地多活解决方案
https://max.book118.com/html/2022/0302/5212310340004143.shtm
搞懂异地多活,看这篇就够了
http://kaito-kidd.com/2021/10/15/what-is-the-multi-site-high-availability-design
https://linpxing.cn/cxy_yididh_gaoky_991
异地多活设计辣么难?其实是你想多了!
https://developer.aliyun.com/article/57715