Kubernetes 内部的架构
原文:https://phoenixnap.com/kb/understanding-kubernetes-architecture-diagrams
Kubernetes是用于管理容器化应用程序集群的工具。在计算机领域中,此过程通常称为编排。
用管弦乐编排比喻上面的服务编排是很恰当的,就像乐队指挥一样,Kubernetes协调地将许多微服务组合在一起构成了应用程序。 Kubernetes会自动且持续地监视集群并对其组成进行调整。
了解Kubernetes架构对于部署和维护容器化的应用程序至关重要。
什么是 Kubernetes
Kubernetes或简称k8s,是一个用于自动执行应用程序部署的系统。现代应用程序分散在云,虚拟机和服务器之间。手动管理应用程序不再是可行的选择。
K8s将虚拟机和物理机转换为统一的API切面。然后,开发人员可以使用Kubernetes API来部署,扩展和管理容器化的应用程序。
它的体系结构还为分布式系统提供了一个灵活的框架。K8s为您的应用程序自动协调扩展和故障转移,并提供部署模式。
它有助于管理运行应用程序的容器,并确保生产环境中没有停机时间。例如,如果某个容器发生故障,则另一个容器会自动取代其位置,而最终用户根本不会注意到。
Kubernetes不仅是一个编排系统。它是一组独立的,相互关联的控制过程。它的作用是在当前状态下连续工作,并朝着期望的方向移动过程。
Kubernetes 架构和组成
Kubernetes具有去中心化的架构,不会线性处理任务。它基于声明性模型运行并实现"所需状态"的概念。下面这些步骤说明了Kubernetes的基本过程:
- 管理员创建应用程序的所需状态并将其放入清单文件
manifest.yml中。 - 使用 CLI 或提供的用户界面将清单文件提供给
Kubernetes API Server。Kubernetes的默认命令行工具称为kubectl。 Kubernetes将清单文件(描述了应用程序的期望状态)存储在称为键值存储(etcd)的数据库中。Kubernetes随后在集群内的所有相关应用程序上实现所需的状态。Kubernetes持续监控集群的元素,以确保应用程序的当前状态不会与所需状态有所不同。
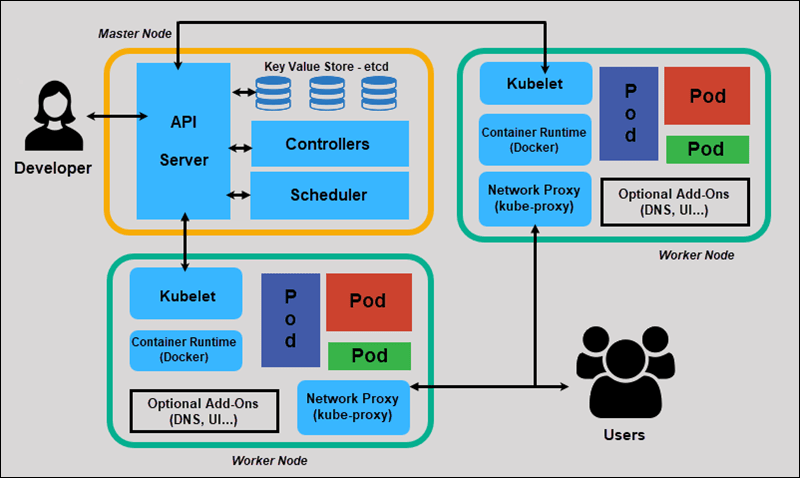
现在,我们将探索标准Kubernetes集群的各个组成部分,以更详细地了解该过程。
主节点
Kubernetes的主节点通过 API 从 CLI(命令行界面)或 UI(用户界面)接收输入。这些是你提供给Kubernetes的命令。
你可以定义想要让Kubernetes维护的Pod,副本集和Service。例如,要使用的容器镜像,要公开的端口以及要运行的Pod副本数量。还可以为该集群中运行的应用程序提供"所需状态"的参数。
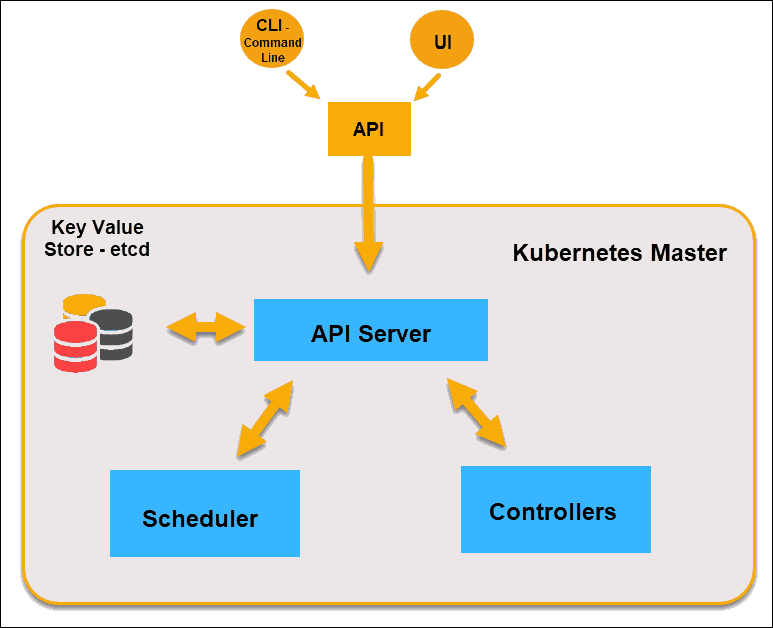
API Server
API Server 是Kubernetes控制程序的前端,也是用户唯一可以直接进行交互的Kubernetes组件,内部系统组件以及外部用户组件均通过相同的 API 进行通信。
键值存储 etcd
键值存储(也称为etcd)是Kubernetes用来备份所有集群数据的数据库。它存储集群的整个配置和状态。主节点查询etcd以检索节点,容器和容器的状态参数。
Controller
控制器的作用是从 API Server 获得所需状态。它检查要控制的节点的当前状态,确定是否与所需状态存在任何差异,并解决它们(如果有)。
Scheduler
调度程序会监视来自 API Server 的新请求,并将其分配给运行状况良好的节点。它对节点的质量进行排名,并将Pod部署到最适合的节点。如果没有合适的节点,则将Pod置于挂起状态,直到出现合适的节点。
注意:最好不要在主节点上运行用户应用程序。让
Kubernetes主节点可以完全专注于管理集群。
工作节点
工作节点监听 API Server 发送过来的新的工作分配;他们会执行分配给他们的工作,然后将结果报告给Kubernetes主节点。
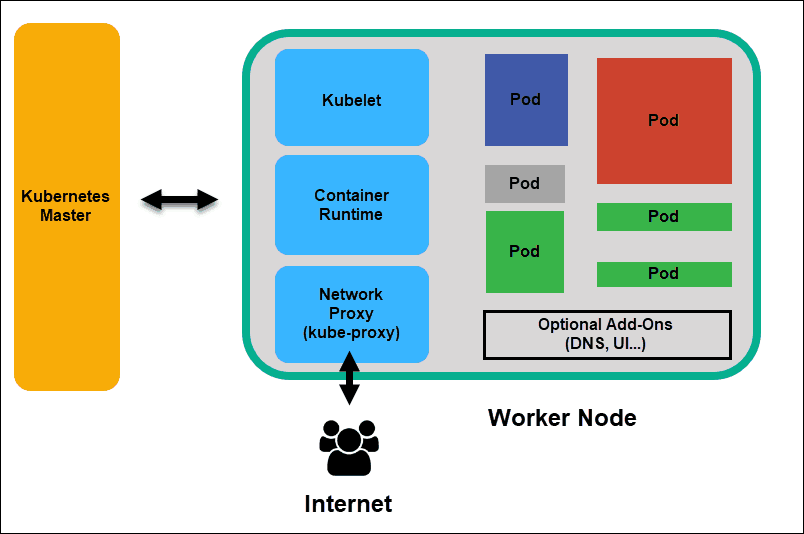
Kubelet
kubelet在群集中的每个节点上运行。它是Kubernetes内部的主要代理。通过安装kubelet,节点的CPU,RAM和存储成为所处集群的一部分。它监视从 API Server 发送来的任务,执行任务,并报告给主节点。它还会监视Pod,如果Pod不能完全正常运行,则会向控制程序报告。然后,基于该信息,主服务器可以决定如何分配任务和资源以达到所需状态。
Container Runtime
容器运行时从容器镜像库中拉取镜像,然后启动和停止容器。容器运行时由第三方软件或插件(例如 Docker)担当。
Kube-proxy
kube-proxy确保每个节点都获得其 IP 地址,实现本地iptables和规则以处理路由和流量负载均衡。
Pod
在Kubernetes中,Pod是调度的最小元素。没有它,容器就不能成为集群的一部分。如果你需要扩展应用程序,则只能通过添加或删除Pod来实现。
Pod是Kubernetes中一个抽象化概念,由一个或多个容器组合在一起得共享资源。根据资源的可用性,主节点会把Pod调度到特定工作节点上,并与容器运行时协调以启动容器。
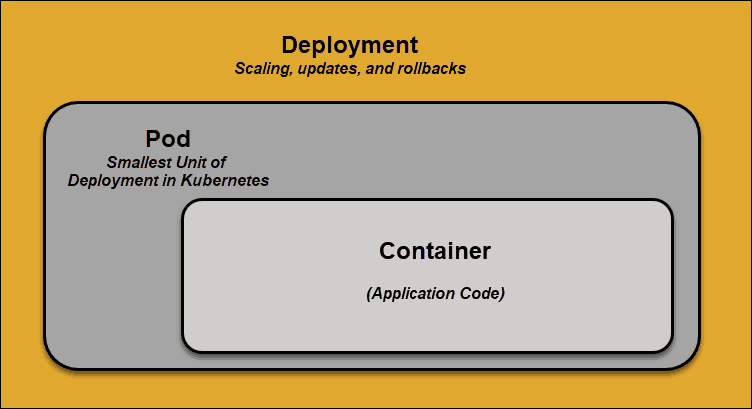
在Pod意外无法执行任务的情况下,Kubernetes不会尝试修复它们。相反,它会在其位置创建并启动一个新Pod。这个新Pod是原来的副本,除了 DNS 和 IP 地址都和以前的Pod一样。此功能对开发人员设计应用程序的方式产生了深远的影响。
由于Kubernetes架构的灵活性,不再需要将应用程序绑定到Pod的特定实例。取而代之的是,需要对应用程序进行设计,以便在集群内任何位置创建的全新 Pod 可以无缝取代旧Pod。Kubernetes会使用Service来协助此过程。
Kubernetes Service
Pod不是恒定的。 Kubernetes提供的最佳功能之一是无法正常运行的Pod会自动被新的Pod取代。
但是,这些新的Pod具有一组不同的 IP。这可能导致处理问题,并且由于 IP 不再匹配,IP 流失。如果无人看管,此属性将使吊舱高度不可靠。
为了将稳定的 IP 地址和 DNS 名称引入到不稳定的 Pod 世界中,Kubernetes引入了Service来提供可靠的网络连接。
通过控制进出Pod的流量,Service提供了稳定的网络终结点-固定的 IP,DNS 和端口。有了Service,可以添加或删除任何Pod,而不必担心基本网络信息会改变。
Service 是怎么工作的
Pod通过称为标签(Label)和选择器(Selector)的键值对与Service相关联。Service会自动发现带有与选择器匹配的标签的新Pod。
此过程无缝地将新的Pod添加到Service,同时,从群集中删除已终止的Pod。
例如,如果所需状态定义了需要一个Pod的三个副本,而运行一个副本的节点发生故障,则当前状态将减少为两个 Pod。Kubernetes观察到所需的状态是三个Pod。然后,它会调度一个新副本来代替发生故障的Pod,并将其分配给集群中的另一个节点。
通过添加或删除容器来更新或缩放应用程序时,同样适用。一旦我们更新了所需状态的定义,Kubernetes就会注意到差异并添加或删除Pod以匹配清单文件manifest.yml里定义的所需状态。Kubernetes控制面板记录,实现和运行后台协调循环,该循环会不断检查环境是否符合用户定义的环境要求。
Container Deployment
为了充分了解Kubernetes的编排方式和内容,我们需要了解一下容器部署的概念。
传统部署
最初,开发人员在单个物理服务器上部署应用程序。这种部署带来的问题是。物理资源的共享意味着一个应用程序可以占用服务器的大部分处理能力,从而限制了同一台服务器上其他应用程序的性能。
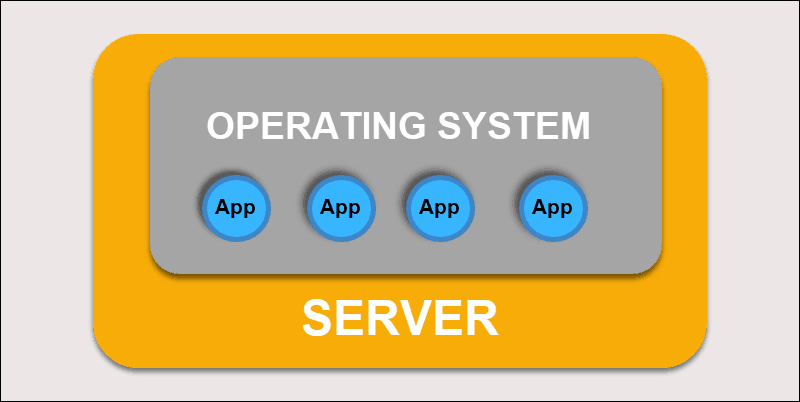
扩展硬件容量需要花费很长时间,增加很多成本。为了解决硬件限制,组织开始虚拟化物理机。
虚拟化部署
虚拟化部署允许在单个物理服务器上创建隔离的虚拟环境,即虚拟机(VM)。该解决方案隔离了 VM 中的应用程序,限制了资源的使用并提高了安全性。一个应用程序不能再自由访问另一个应用程序处理的信息。
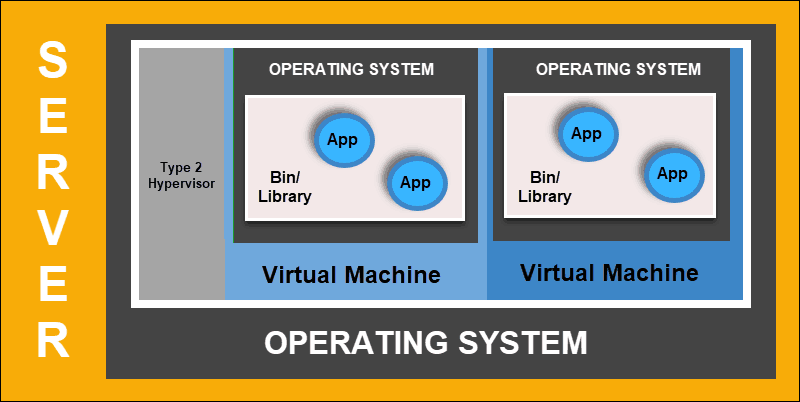
通过虚拟化部署,您可以快速扩展并分散单个物理服务器的资源,随意更新并控制硬件成本。每个 VM 都有其操作系统,并且可以在虚拟化硬件之上运行所有必要的系统。
容器化部署
容器部署是创建更加灵活和高效的模型的下一步。就像虚拟机一样,容器具有单独的内存,系统文件和处理空间。但是,严格隔离不再是限制因素。
现在,多个应用程序可以共享相同的基础操作系统。此功能使容器比成熟的 VM 效率更高。它们可跨越云,不同的设备以及几乎所有OS发行版进行移植。
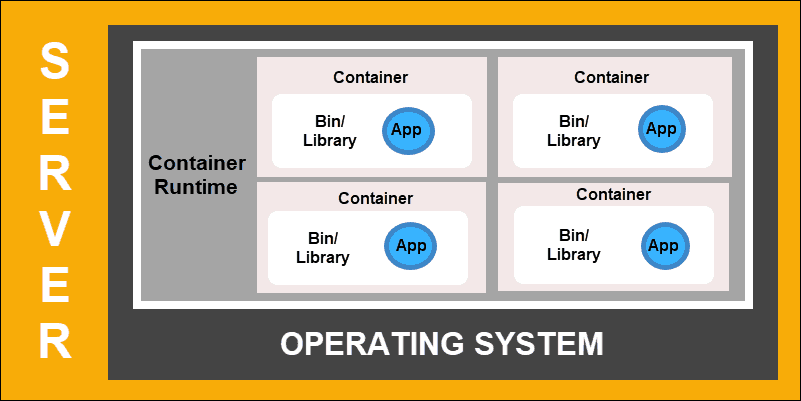
容器的结构还允许应用程序作为较小的独立部分运行。然后可以在多台计算机上动态部署和管理这些部分。复杂的结构和任务划分太复杂,无法手动管理。需要一个像Kubernetes这样的自动化解决方案,以有效管理此过程中涉及的所有活动部件。
总结
Kubernetes使用非常简单的模型进行操作。我们输入希望系统运行的方式–所需状态,Kubernetes将所需状态与集群中的当前状态进行比较。然后,它的服务将两个状态对齐,并实现和维持所需状态。
你现在应该对Kubernetes架构有了更好的了解,可以继续学习执行创建和维护集群的实际任务。