K8S
Linux网络虚拟化
Linux的namespace(名字空间)的作用就是“隔离内核资源”。在Linux的世界里,文件系统挂载点、主机名、POSIX进程间通信消息队列、进程PID数字空间、IP地址、user ID数字空间等全局系统资源被namespace分割,装到一个个抽象的独立空间里。而隔离上述系统资源的namespace分别是Mountnamespace、UTS namespace、IPC namespace、PID namespace、networknamespace和user namespace。对进程来说,要想使用namespace里面的资源,首先要“进入”(具体操作方法,下文会介绍)到这个namespace,而且还无法跨namespace访问资源。Linux的namespace给里面的进程造成了两个错觉:
(1)它是系统里唯一的进程。
(2)它独享系统的所有资源。
默认情况下,Linux进程处在和宿主机相同的namespace,即初始的根namespace里,默认享有全局系统资源。
每个网络namespace里都有自己的网络设备(如IP地址、路由表、端口范围、/proc/net目录等)。从网络的角度看,network namespace使得容器非常有用,一个直观的例子就是:由于每个容器都有自己的(虚拟)网络设备,并且容器里的进程可以放心地绑定在端口上而不必担心冲突。
和其他namespace一样,network namespace可以通过系统调用来创建,我们可以调用Linux的clone()(其实是UNIX系统调用fork()的延伸)API创建一个通用的namespace,然后传入CLONE_NEWNET参数表面创建一个networknamespace。
创建一个名为netns1的network namespace可以使用以下命令:
ip netns add netns1当ip命令创建了一个network namespace时,系统会在/var/run/netns路径下面生成一个挂载点。挂载点的作用一方面是方便对namespace的管理,另一方面是使namespace即使没有进程运行也能继续存在。
一个network namespace被创建出来后,可以使用ip netns exec命令进入,做一些网络查询/配置的工作。
[root@192 netns]# ip netns exec netns1 ip link list
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
目前,我们没有任何配置,因此只有一块系统默认的本地回环设备lo。而且处于state DOWN状态。
处于DOWN状态的lo设备无法访问本地回环,网络也是不通的。
[root@192 netns]# ip netns exec netns1 ping 127.0.0.1
connect: Network is unreachable首先需要进入netns1这个networknamespace,把设备状态设置成UP,这个时候本地回环才能使用。
ip netns exec netns1 ip link set dev lo up仅有一个本地回环设备是没法与外界通信的。如果我们想与外界(比如主机上的网卡)进行通信,就需要在namespace里再创建一对虚拟的以太网卡,即所谓的veth pair。
ip link add veth0 type veth peer name veth1
ip link set veth1 netns netns1
## 刚创建的veth0,veth1都在主机的namespace根目录下,并且处于DOWN状态
## 为veth1绑定IP地址10.1.1.1/24 状态设置成UP
ip netns exec netns1 ifconfig veth1 10.1.1.1/24 up
## 主机根network namespace中的网卡veth0被我们绑定了IP地址10.1.1.2/24
ifconfig veth0 10.1.1.2/24 up
## 在主机ping 10.1.1.1
[root@192 netns]# ping 10.1.1.1
PING 10.1.1.1 (10.1.1.1) 56(84) bytes of data.
64 bytes from 10.1.1.1: icmp_seq=1 ttl=64 time=0.050 ms
64 bytes from 10.1.1.1: icmp_seq=2 ttl=64 time=0.044 ms
## 在netns1 network namespace ping 主机虚拟网卡
0.1.1.2 (10.1.1.2) 56(84) bytes of data.
64 bytes from 10.1.1.2: icmp_seq=1 ttl=64 time=0.049 ms
64 bytes from 10.1.1.2: icmp_seq=2 ttl=64 time=0.047 ms
不同network namespace之间的路由表和防火墙规则等也是隔离的。
[root@192 netns]# ip netns exec netns1 route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.1.1.0 0.0.0.0 255.255.255.0 U 0 0 0 veth1
[root@192 netns]# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 192.168.44.2 0.0.0.0 UG 100 0 0 ens33
10.1.1.0 0.0.0.0 255.255.255.0 U 0 0 0 veth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.44.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 virbr0
root@192 netns]# ip netns exec netns1 iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
我们进入netns1 network namespace,分别输入route和iptables-L命令,期望查询路由表和iptables规则,却发现空空如也。这意味着从netns1network namespace发包到因特网也是徒劳的,因为网络还不通!不信读者可以自行尝试。想连接因特网,有若干解决方法。例如,可以在主机的根networknamespace创建一个Linux网桥并绑定veth pair的一端到网桥上;也可以通过适当的NAT(网络地址转换)规则并辅以Linux的IP转发功能(配置net.ipv4.ip_forward=1)。
需要注意的是,用户可以随意将虚拟网络设备分配到自定义的networknamespace里,而连接真实硬件的物理设备则只能放在系统的根networknamesapce中。并且,任何一个网络设备最多只能存在于一个networknamespace中。
veth
veth是虚拟以太网卡(Virtual Ethernet)的缩写。veth设备总是成对的,因此我们称之为veth pair。veth pair一端发送的数据会在另外一端接收,非常像Linux的双向管道。根据这一特性,veth pair常被用于跨network namespace之间的通信,即分别将veth pair的两端放在不同的namespace里。
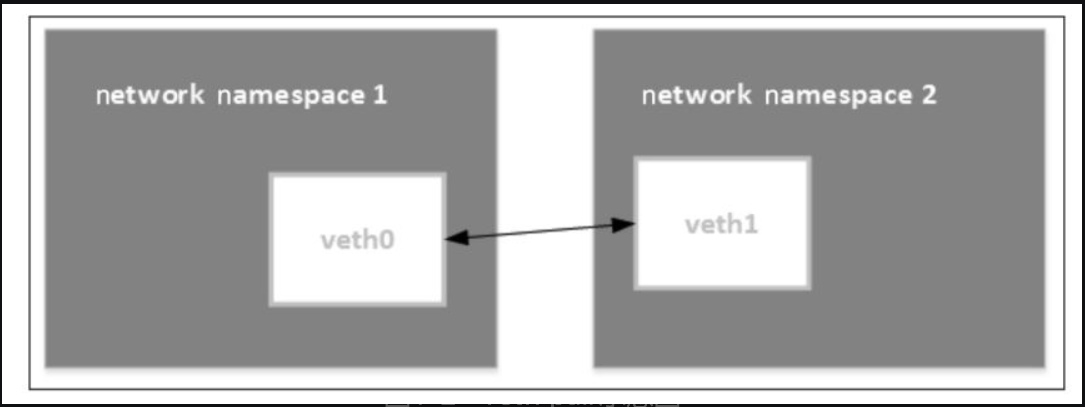
仅有veth pair设备,容器是无法访问外部网络的。为什么呢?因为从容器发出的数据包,实际上是直接进了veth pair设备的协议栈。如果容器需要访问网络,则需要使用网桥等技术将veth pair设备接收的数据包通过某种方式转发出去。
创建和使用veth pair:
ip link add veth0 type veth peer name veth1
[admin@192 ~]$ ip link show veth0
7: veth0@veth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether e2:44:56:c7:56:18 brd ff:ff:ff:ff:ff:ff
[admin@192 ~]$ ip link show veth1
6: veth1@veth0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether ca:38:ea:b8:25:55 brd ff:ff:ff:ff:ff:ff
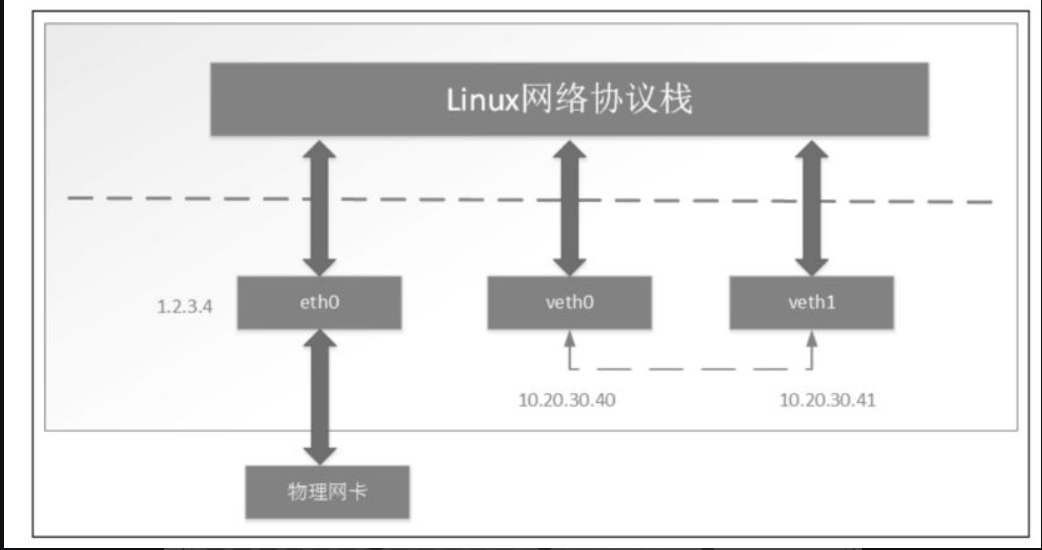
## 新创建的veth pair设备的默认mtu是1500,设备初始状态是DOWN。我们同样可以使用ip link命令将这两块网卡的状态设置为UP。
ip link set dev veth0 up
ip link set dev veth1 up
## 配置ip地址
ifconfig veth0 10.20.30.40/24
## 可以将veth pair 设备放到namespace中
ip link set veth1 netns newns
veth pair设备的原理较简单,就是向veth pair设备的一端输入数据,数据通过内核协议栈后从veth pair的另一端出来.
Linux bridge
两个network namespace可以通过veth pair连接,但要做到两个以上networknamespace相互连接,veth pair就显得捉襟见肘了,就需要使用到Linux bridge。
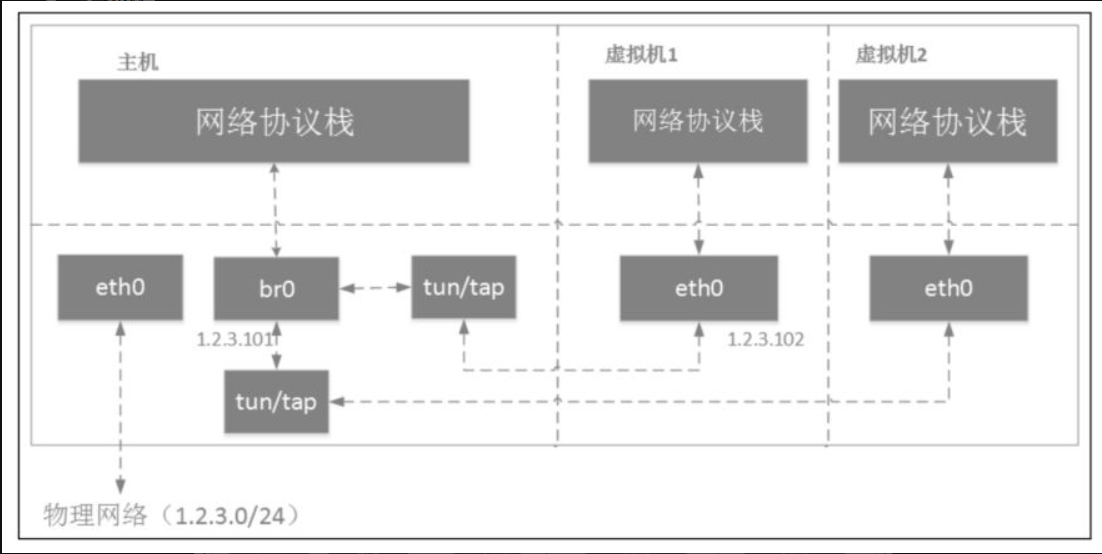
Linux bridge就是Linux系统中的网桥,但是Linux bridge的行为更像是一台虚拟的网络交换机,任意的真实物理设备(例如eth0)和虚拟设备(例如,前面讲到的veth pair和后面即将介绍的tap设备)都可以连接到Linux bridge上。需要注意的是,Linux bridge不能跨机连接网络设备。
Linux bridge与Linux上其他网络设备的区别在于,普通的网络设备只有两端,从一端进来的数据会从另一端出去。例如,物理网卡从外面网络中收到的数据会转发给内核协议栈,而从协议栈过来的数据会转发到外面的物理网络中。Linux bridge则有多个端口,数据可以从任何端口进来,进来之后从哪个口出去取决于目的MAC地址,原理和物理交换机差不多。
虚拟机通过tun/tap或者其他类似的虚拟网络设备,将虚拟机内的网卡同br0连接起来,这样就达到和真实交换机一样的效果,虚拟机发出去的数据包先到达br0,然后由br0交给eth0发送出去,数据包都不需要经过host机器的协议栈,效率高。
容器运行在自己单独的network namespace里,因此都有自己单独的协议栈。Linux bridge在容器场景的组网和上面的虚拟机场景差不多,但也存在一些区别。例如,容器使用的是veth pair设备,而虚拟机使用的是tun/tap设备。在虚拟机场景下,我们给主机物理网卡eth0分配了IP地址;而在容器场景下,我们一般不会对宿主机eth0进行配置。在虚拟机场景下,虚拟器一般会和主机在同一个网段;而在容器场景下,容器和物理网络不在同一个网段内。
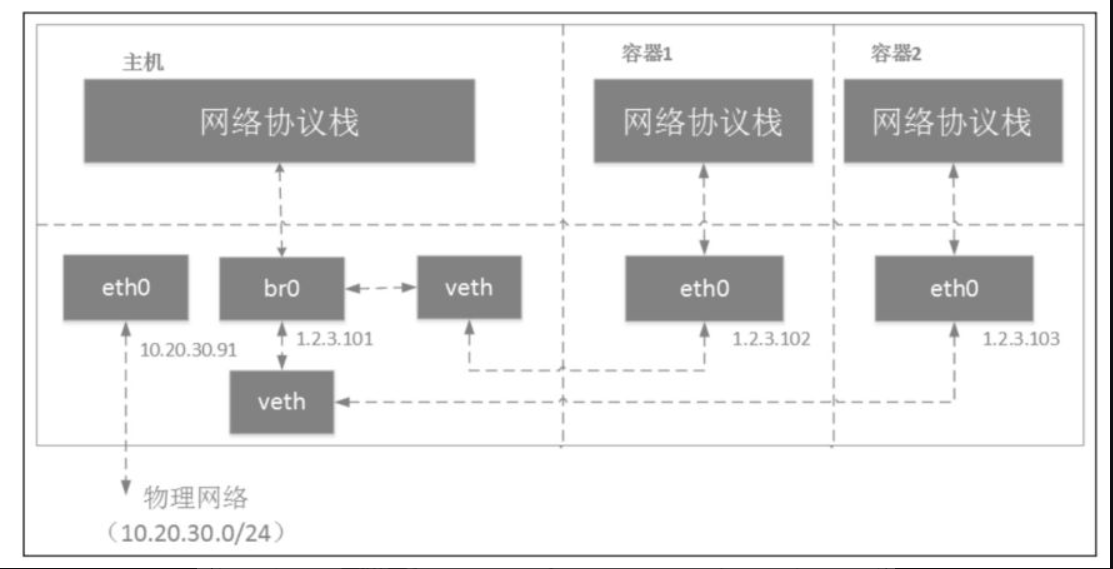
在容器中配置其网关地址为br0,从容器发出去的数据包先到达br0,然后交给host机器的协议栈。由于目的IP是外网IP,且host机器开启了IP forward功能,数据包会通过eth0发送出去。因为容器所分配的网段一般都不在物理网络网段内(在我们的例子中,物理网络网段是10.20.30.0/24),所以一般发出去之前会先做NAT转换。
网络接口的混杂模式:混杂模式(Promiscuous mode),简称Promisc mode,俗称“监听模式”。混杂模式通常被网络管理员用来诊断网络问题,但也会被无认证的、想偷听网络通信的人利用。根据维基百科的定义,混杂模式是指一个网卡会把它接收的所有网络流量都交给CPU,而不是只把它想转交的部分交给CPU。在IEEE 802定的网络规范中,每个网络帧都有一个目的MAC地址。在非混杂模式下,网卡只会接收目的MAC地址是它自己的单播帧,以及多播及广播帧;在混杂模式下,网卡会接收经过它的所有帧!
tun/tap
tun/tap设备到底是什么?从Linux文件系统的角度看,它是用户可以用文件句柄操作的字符设备;从网络虚拟化角度看,它是虚拟网卡,一端连着网络协议栈,另一端连着用户态程序。
tun/tap设备有什么作用呢?tun/tap设备可以将TCP/IP协议栈处理好的网络包发送给任何一个使用tun/tap驱动的进程,由进程重新处理后发到物理链路中。tun/tap设备就像是埋在用户程序空间的一个钩子,我们可以很方便地将对网络包的处理程序挂在这个钩子上,OpenVPN、Vtun、flannel都是基于它实现隧道包封装的。
tun/tap设备的工作原理:
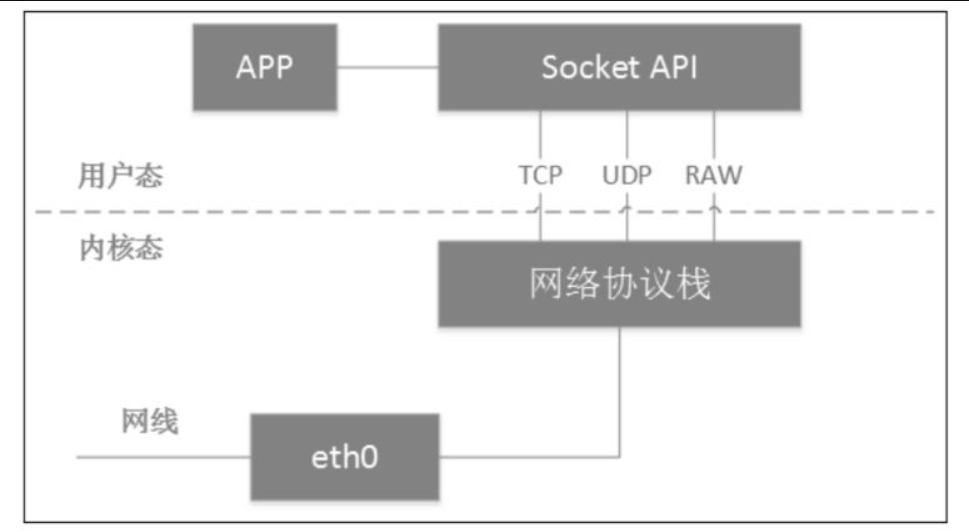
通过Socket调用实现用户态和内核态数据交互的过程。物理网卡从网线接收数据后送达网络协议栈,而进程通过Socket创建特殊套接字,从网络协议栈读取数据。
从网络协议栈的角度看,tun/tap设备这类虚拟网卡与物理网卡并无区别。只是对tun/tap设备而言,它与物理网卡的不同表现在它的数据源不是物理链路,而是来自用户态!这也是tun/tap设备的最大价值所在。
tun/tap设备其实就是利用Linux的设备文件实现内核态和用户态的数据交互,而访问设备文件则会调用设备驱动相应的例程,要知道设备驱动也是内核态和用户态的一个接口.
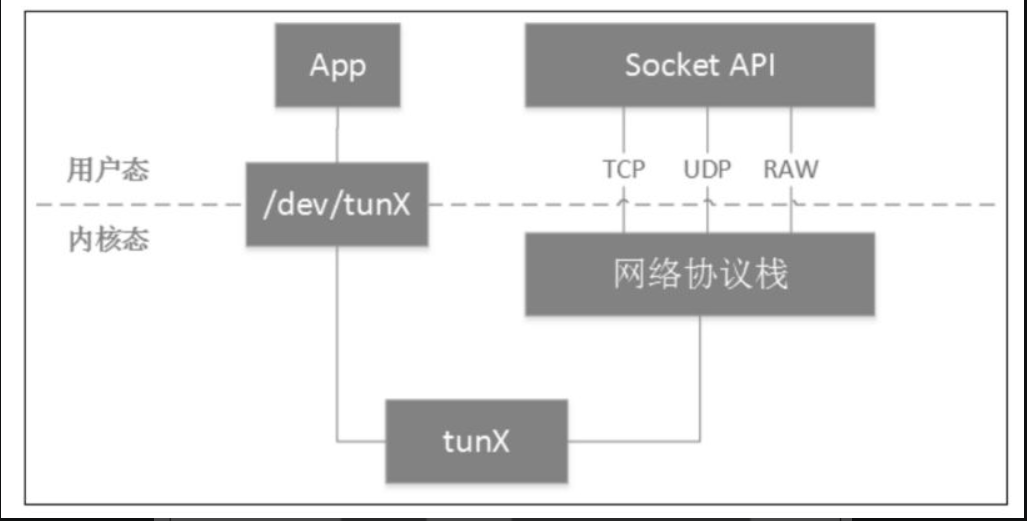
普通的物理网卡通过网线收发数据包,而tun设备通过一个设备文件(/dev/tunX)收发数据包。所有对这个文件的写操作会通过tun设备转换成一个数据包传送给内核网络协议栈。当内核发送一个包给tun设备时,用户态的进程通过读取这个文件可以拿到包的内容。当然,用户态的程序也可以通过写这个文件向tun设备发送数据。
tap设备与tun设备的工作原理完全相同,区别在于:
-
tun设备的/dev/tunX文件收发的是IP包,因此只能工作在L3,无法与物理网卡做桥接,但可以通过三层交换(例如ip_forward)与物理网卡连通;
-
tap设备的/dev/tapX文件收发的是链路层数据包,可以与物理网卡做桥接。
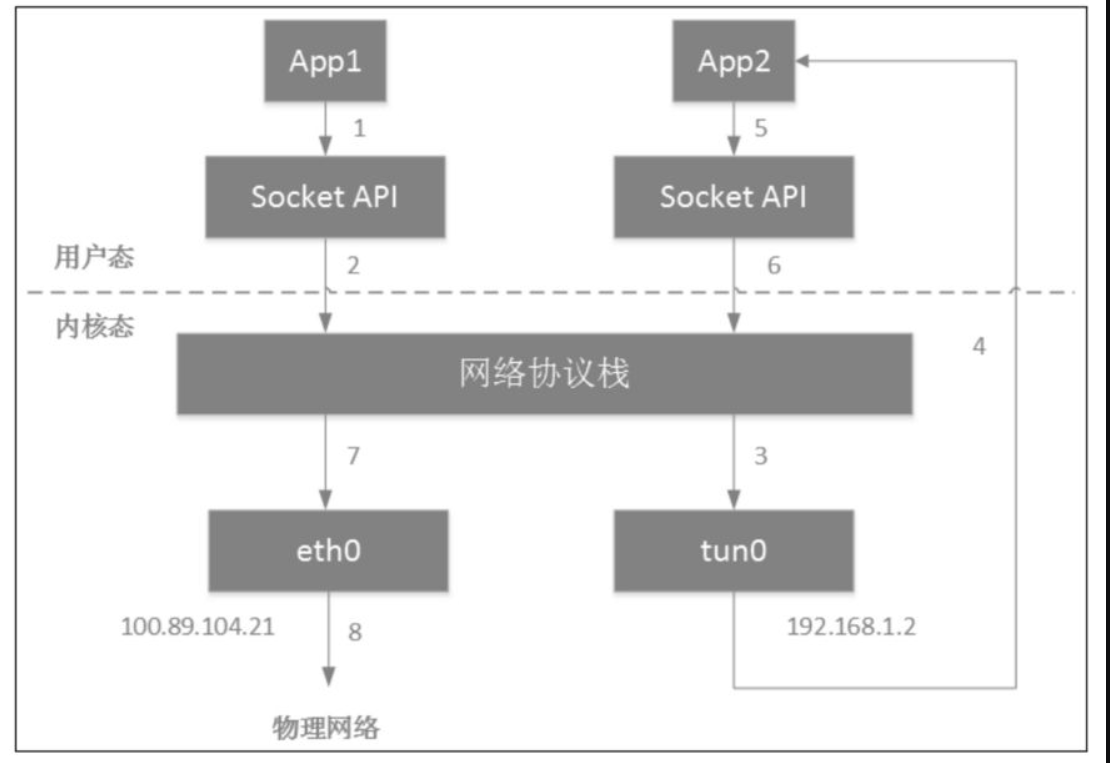
tun设备的tun是英文隧道(tunnel)的缩写,言下之意,tun设备似乎与隧道网络存在一丝联系。tun/tap设备的用处是将协议栈中的部分数据包转发给用户空间的应用程序,给用户空间的程序一个处理数据包的机会。常见的tun/tap设备使用场景有数据压缩、加密等,最常见的是VPN,包括tunnel及应用层的IPSec等。
下图为简单的UDP的VPN网络拓扑。
iptables
iptables在Docker和Kubernetes网络中应用甚广。Docker容器和宿主机的端口映射、Kubernetes Service的默认模式、CNI的portmap插件、Kubernetes网络策略等都是通过iptables实现的。
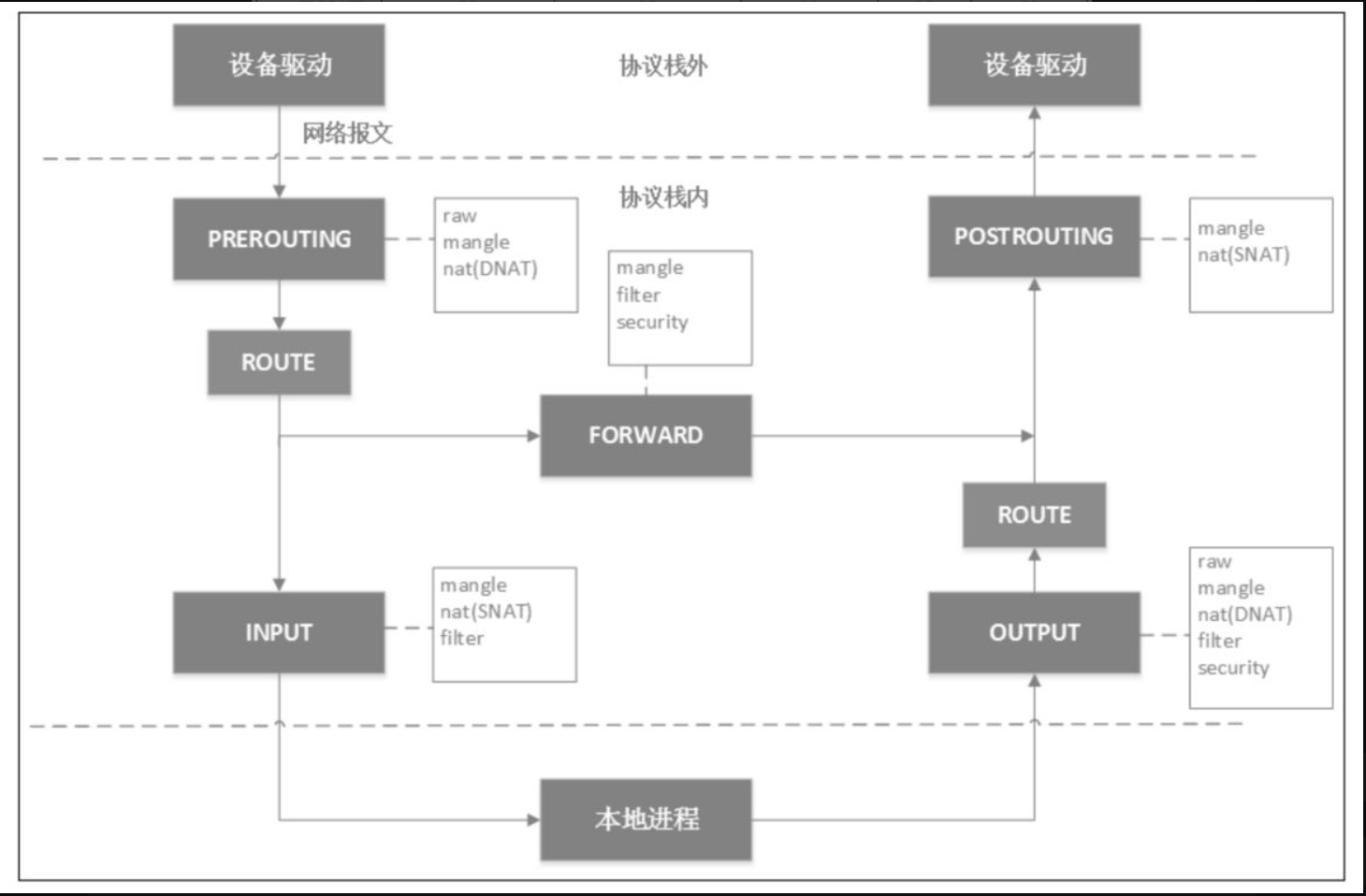
iptables的底层实现是netfilter。IP层的5个钩子点的位置,对应iptables就是5条内置链,分别是PREROUTING、POSTROUTING、INPUT、OUTPUT和FORWARD。netfilter原理图如图:
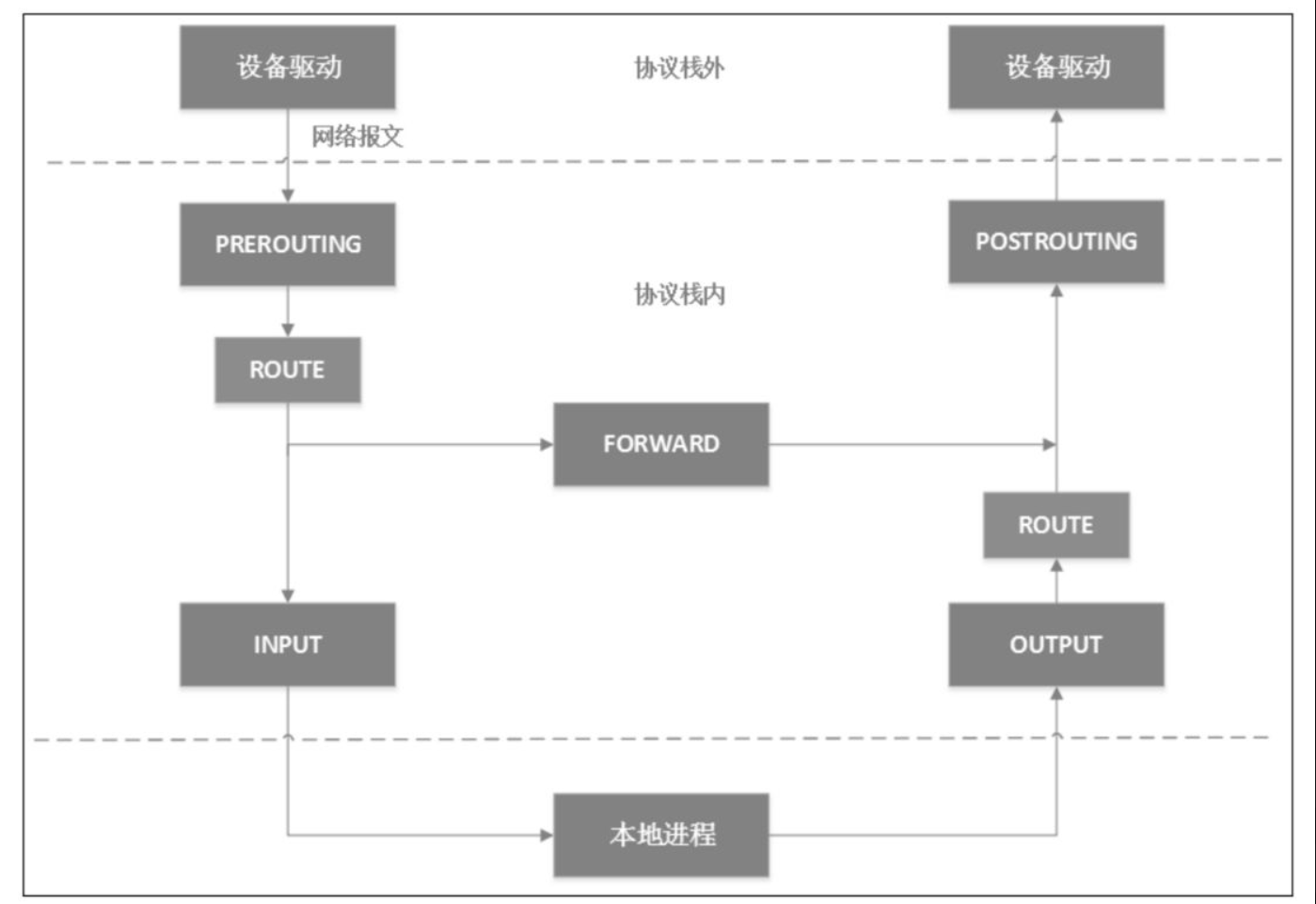
当网卡上收到一个包送达协议栈时,最先经过的netfilter钩子是PREROUTING,如果确实有用户埋了这个钩子函数,那么内核将在这里对数据包进行目的地址转换(DNAT)。不管在PREROUTING有没有做过DNAT,内核都会通过查本地路由表决定这个数据包是发送给本地进程还是发送给其他机器。如果是发送给其他机器(或其他network namespace),就相当于把本地当作路由器,就会经过netfilter的FORWARD钩子,用户可以在此处设置包过滤钩子函数,例如iptables的reject函数。所有马上要发到协议栈外的包都会经过POSTROUTING钩子,用户可以在这里埋下源地址转换(SNAT)或源地址伪装(Masquerade,简称Masq)的钩子函数。如果经过上面的路由决策,内核决定把包发给本地进程,就会经过INPUT钩子。本地进程收到数据包后,回程报文会先经过OUTPUT钩子,然后经过一次路由决策(例如,决定从机器的哪块网卡出去,下一跳地址是多少等),最后出协议栈的网络包同样会经过POSTROUTING钩子。
Kubernetes网络之间用到的工具就有ebtables、iptables/ip6tables和conntrack,其中iptables是核心。
table、chain和rule:
iptables是用户空间的一个程序,通过netlink和内核的netfilter框架打交道,负责往钩子上配置回调函数。
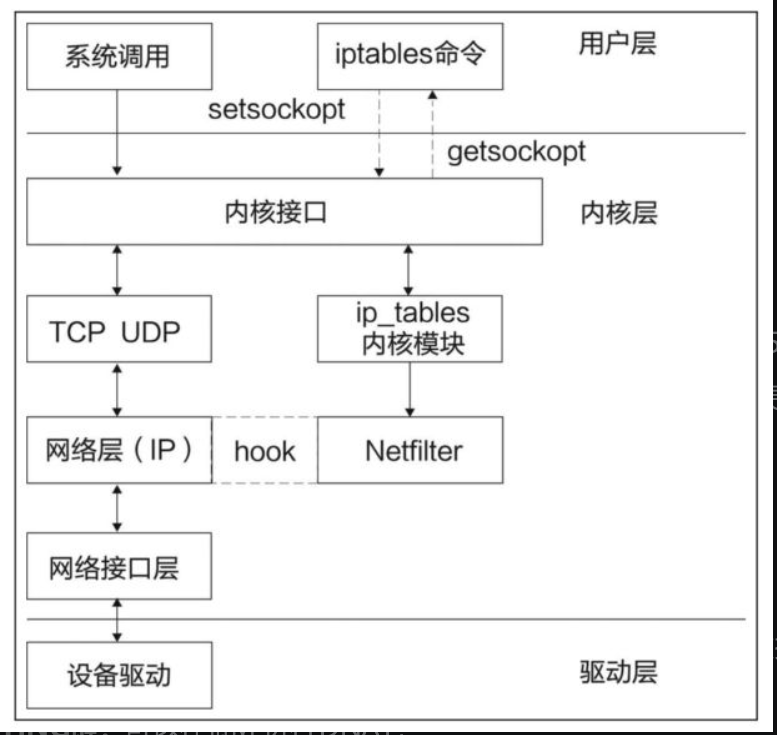
我们常说的iptables 5X5,即5张表(table)和5条链(chain)。5条链即iptables的5条内置链,对应上文介绍的netfilter的5个钩子。这5条链分别是:
-
INPUT链:一般用于处理输入本地进程的数据包;
-
OUTPUT链:一般用于处理本地进程的输出数据包;
-
FORWARD链:一般用于处理转发到其他机器/network namespace的数据包;
-
PREROUTING链:可以在此处进行DNAT;
-
POSTROUTING链:可以在此处进行SNAT。
5张表如下所示。
-
filter表:用于控制到达某条链上的数据包是继续放行、直接丢弃(drop)或拒绝(reject);
-
nat表:用于修改数据包的源和目的地址;
-
mangle表:用于修改数据包的IP头信息;
-
raw表:iptables是有状态的,即iptables对数据包有连接追踪(connectiontracking)机制,而raw是用来去除这种追踪机制的;
-
security表:最不常用的表(通常,我们说iptables只有4张表,security表是新加入的特性),用于在数据包上应用SELinux。
一个网络包经过iptables的处理路径如图:
常见的动作有下面几个:
-
DROP:直接将数据包丢弃,不再进行后续的处理。应用场景是不让某个数据源意识到你的系统的存在,可以用来模拟宕机;
-
REJECT:给客户端返回一个connection refused或destination unreachable报文。应用场景是不让某个数据源访问你的系统,善意地告诉他:我这里没有你要的服务内容;
-
QUEUE:将数据包放入用户空间的队列,供用户空间的程序处理;
-
RETURN:跳出当前链,该链里后续的规则不再执行;
-
ACCEPT:同意数据包通过,继续执行后续的规则;·JUMP:跳转到其他用户自定义的链继续执行。
iptables命令:
## 查看默认规则(默认为filter表的所有规则)
iptables -L -n
## 查看nat表中的规则
iptables -t nat -L -n## 允许流入
iptables -A INPUT -s 10.20.30.40/24 -p tcp -dport 22 -j ACCEPT
## 阻止流入,无响应
iptables -A INPUT -s 10.20.30.40/24 -J DROP
## 拒绝流入,有响应,响应为拒绝连接
iptables -A INPUT -s 10.20.30.40/24 -J REJECT
## 阻止流出
iptables -A OUTPUT -p tcp --dport 1234 -j DROP
## 转发
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j REDIRECT --to-port 8080
## 禁用 PING
iptables -A INPUT -p icmp -j DROP
## 删除规则
iptables -F
## 指定表删除
iptables -t nat -F
## 删除指定规则
iptables -D INPUT -s 10.10.10.10 -j DROP
## DNAT 和转发类似,但是转发不需要更改ip地址 如果要匹配网卡,可以用-i eth0指定收到包的网卡(i是input的缩写)。
## 需要注意的是,DNAT只发生在nat表的PREROUTING链,这也是我们要指定收到包的网卡而不是发出包的网卡的原因。
iptables -t nat -A PREROUTING -d 1.2.3.4 -p -tcp -dport 80 -j DNAT --to-destination 10.20.30.40:8080
## 需要注意的是,当涉及转发的目的IP地址是外机时,需要确保启用ip forward功能,即把Linux当交换机用,命令如下:
echo 1 > /proc/sys/net/ipv4/ip_forward-A的意思是以追加(Append)的方式增加这条规则。-A INPUT表示这条规则挂在INPUT链上,-A OUTPUT表示挂载在OUTPUT规则上。-s 10.20.30.40/24表示允许源(source)地址是10.20.30.40/24这个网段的连接。-p tcp表示允许TCP(protocol)包通过。--dport 22的意思是允许访问的目的端口(destination port)为22,即SSH端口。-j ACCEPT表示接受这样的连接,-j DROP表示组织,-j REJECT表示拒绝(会发送拒绝响应包)。综上所述,这条iptables规则的意思是允许源地址是10.20.30.40/24这个网段的包发到本地TCP 22端口。除了按追加的方式添加规则,还可以使用iptables-I[chain][number]将规则插入(Insert)链的指定位置。如果不指定number,则插到链的第一条处。
Linux隧道网络
待添加
Docker网络模型
容器: 容器不是模拟一个完整的操作系统,而是对进程进行隔离,隔离用到的技术就是Linux namespace。对容器里的进程来说,它接触到的各种资源看似是独享的,但在底层其实是隔离的。容器是进程级别的隔离技术,因此相比虚拟机有启动快、占用资源少、体积小等优点。
Docker的四大网络模式
从网络的角度看容器,就是network namespace+容器的组网方案。
我们在使用docker run命令创建Docker容器时,可以使用--network选项指定容器的网络模式。
在安装完Docker之后,Docker Daemon会在宿主机上自动创建三个网络,分别是bridge网络、host网络和none网络,可以使用docker network ls命令查看:
root@localhost ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
275d07e7c9ee bridge bridge local
65e7ca841df7 host host local
fb44db4e5e43 none null local
Docker有以下4种网络模式:
-
bridge模式,通过--network=bridge指定;
Docker在安装时会创建一个名为docker0的Linux网桥。bridge模式是Docker默认的网络模式,在不指定--network的情况下,Docker会为每一个容器分配networknamespace、设置IP等,并将Docker容器连接到docker0网桥上。严谨的表述是,创建的容器的veth pair中的一端桥接到docker0上。docker0网桥是普通的Linux网桥,而非OVS网桥。
## 查看网桥信息【无任何对接的网卡信息】 root@localhost ~]# brctl show bridge name bridge id STP enabled interfaces docker0 8000.02426060b578 no virbr0 8000.5254001c2114 yes virbr0-nic ## 创建容器后可以看到有对接网卡信息 [root@localhost ~]# brctl show bridge name bridge id STP enabled interfaces docker0 8000.02426060b578 no vethaf70928 virbr0 8000.5254001c2114 yes virbr0-nic访问非本机容器网段要经过docker0网关转发,而同主机上的容器(同网段)之间通过广播通信,不仅如此,发到主机上要访问Docker容器的报文默认也要经过docker0进行广播。
-
host模式,通过--network=host指定;
连接到host网络的容器共享Docker host的网络栈,容器的网络配置与host完全一样。host模式下容器将不会获得独立的network namespace,而是和宿主机共用一个network namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。

-
container模式,通过--network=container:NAME_or_ID指定,即joiner容器;
container模式指定新创建的容器和已经存在的任意一个容器共享一个network namespace,但不能和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的IP,而是和一个指定的容器共享IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过lo网卡设备通信。Kubernetes的Pod网络采用的就是Docker的container模式网络。
-
none模式,通过--network=none指定。
none模式下的容器只有lo回环网络,没有其他网卡。
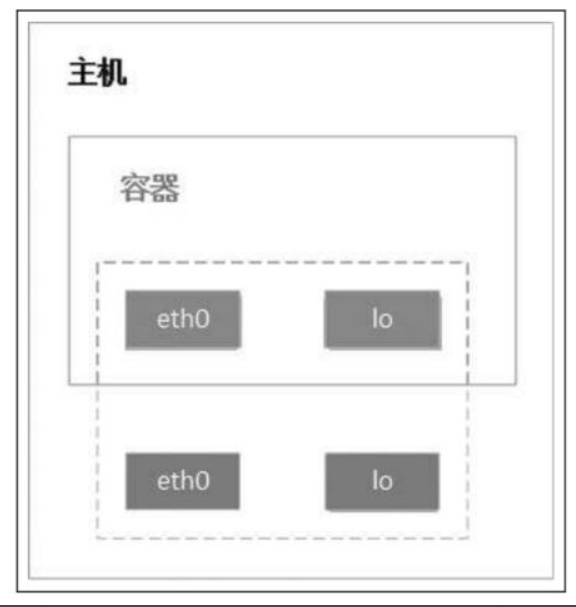
常用命令:
## 查看容器ip
[root@localhost ~]# docker inspect -f "{{ .NetworkSettings.IPAddress }}" es
172.17.0.2
[root@localhost ~]# docker inspect es | grep '"IPAddress"' |head -n 1
"IPAddress": "172.17.0.2",
## 端口映射 -p的格式是hostport:containerport,Docker容器端口映射原理都是在本地的iptable的nat表中添加相应的规则,
## 将访问本机IP地址:hostport的网包进行一次DNAT,转换成容器IP:containerport
docker run -p 9300:9300 -d es
[root@localhost ~]# iptables -t nat -nL
t prot opt source destination
RETURN all -- 0.0.0.0/0 0.0.0.0/0
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:9300 to:172.17.0.2:9300
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:9200 to:172.17.0.2:9200
##访问外网,默认模式为bridge,通过dokcer0进行桥接,不需要配置,其他模式使用ip_forward和SNAT/MASQUERADE,
## 或者启动docker时--ip-forward=true
sysctl net.ipv4.ip_forward=1
net.ipv4.ip_forward=1
## 自定义网路
docker network create -d bridge --subnet 172.25.0.0/16 mynet
docker network inspect {id}
## 删除网络
docker network rm {id}
## 连接网络
docker network connect mynet {containername}
## 断开网络
docker network disconnect
## 发布服务
docker network create -d brige foo
docker service publish my-service.foo
docker service attach {container-id} myservice.foo
## 发布服务
docker run -itd --publish-service db.foo.brige busybox
## 指定容器名
docker run -d busybox --name busyboxtest
## 修改容器名
docker exec 6f5 hostname test123
## 修改后检索
dokcer inspect 6f5 |grep Pid
"Pid" : 123.
ll /proc/123/ns/
DNS
容器中的DNS和主机名一般通过三个系统配置文件维护,分别是/etc/resolv.conf、/etc/hosts和/etc/hostname,其中:
-
/etc/resolv/conf在创建容器的时候,默认与本地主机/etc/resolv.conf保持一致;
-
/etc/hosts中则记载了容器自身的一些地址和名称;
-
/etc/hostname中记录容器的主机名。
但是修改只能当前运行时生效,如果需要永久生效需要修改修改主机Docker Daemon的配置文件(一般是/etc/docker/daemon.json)的方式指定除主机/etc/resolv.conf的其他DNS信息,也可以在docker run时使用--dns=address参数来指定。
{
"dns":[
"114.114.114.114",
"8.8.8.8"
]
}原生Docker容器网络的组网模型比较简单,主要是单主机模式,它基于以下几个简单的假定:
-
它充分利用与容器相连接的本地Linux网桥;
-
每个宿主机都有集群看得见的公共IP地址;
-
每个容器都有集群看不见的专有的IP地址;
-
通过NAT将容器的专有IP地址绑定到宿主机公共IP地址上;
-
iptable用于容器与用户基础网络之间的网络隔离;
-
负载均衡系统将服务映射至一组容器IP地址和端口。
·原生Docker容器不解决跨主机通信问题
容器相较虚拟机生命周期更短,重启更加频繁,重启后IP地址将发生变化,需要进行高效的网络地址管理,因此静态的IP地址分配或DHCP(耗费数秒才能生效)将不起作用;
在创建虚拟机的时候,IP地址的分配是一种静态方式。但是在容器上面,IP地址的分配通常是动态的。在创建容器时,通常我们不知道它的IP是什么,只有真正运行后才能知道;
大规模部署使用veth设备会影响网络性能,最严重时甚至会比裸机降低50%;
....
容器组网方案
隧道方案
路由方案
kubernetes
真实的生产环境应用会包含多个容器,而这些容器很可能会跨越多个服务器部署。Kubernetes提供了容器大规模部署、编排与管理的能力。Kubernetes提供的工作负载抽象能够让用户非常方便地构建多容器的应用服务,并且支持弹性伸缩、滚动升级和健康检查等功能。
一个初步的Linux容器应用程序把容器视作高效、快速的虚拟机。一旦把它部署到生产环境或者扩展为多个应用,随着这些容器的累积,运行环境中容器的数量就会急剧增加,复杂度也随之增大。因此,Kubernetes通常需要与镜像仓库、网络、存储、安全、监控告警等其他服务集成才能提供综合性的容器基础设施,如图:
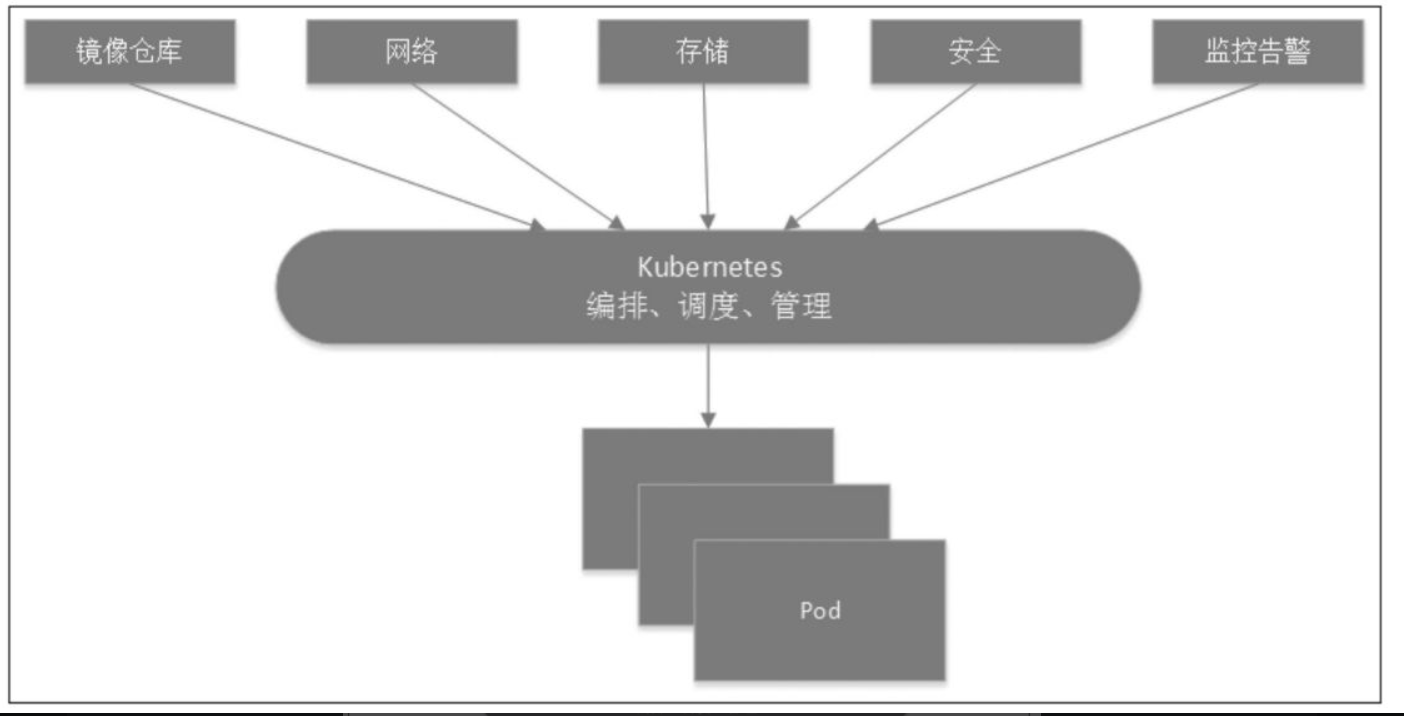
Kubernetes通过将容器分类组成Pod。Pod是Kubernetes中特有的一个概念,它是容器分组的一层抽象,也是Kubernetes最小的部署单元。Kubernetes基于Pod提供工作负载的概念及网络、存储等能力。K8S中的一些术语:
-
Master(主节点):控制Kubernetes工作节点的机器,运行着Kubernetes的管理面,也是创建Kubernetes工作负载的地方;
-
Node(工作节点):这些机器在Kubernetes主节点的控制下将工作负载以容器的方式运行起来;
-
Pod:由一个或多个容器构成的集合,作为一个整体被部署到一个节点上。同一个Pod中的容器共享网络协议栈、进程间通信(IPC)、主机名、存储其他资源。Kubernetes的Pod概念使得用户能够方便地对一组功能相似的容器的网络、存储、迁移和生命周期等进行管理。Pod运行一个或多个容器,节点运行零个或多个Pod;·Replication Controller/Replication Set:控制Pod在集群上运行的副本数量;
-
Service(服务):将服务访问信息与具体的Pod解耦。Kubernetes服务代理负责自动将服务请求分发到正确的后端Pod处;
-
Kubelet:守护进程,运行在每个工作节点上,保证该节点上容器的正常运行;
-
kubectl:Kubernetes的命令行工具。
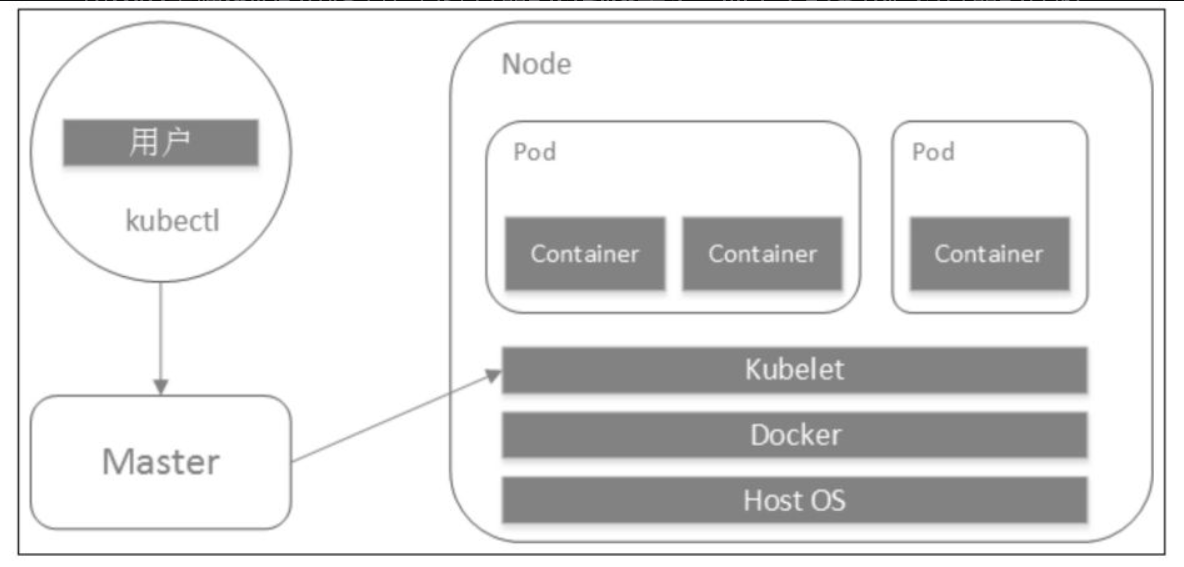
Pod内不同容易之间共享存储和一些namespace,具体资源有:
-
PID命名空间:Pod中的不同应用程序可以看到其他应用程序的进程ID;
-
网络命名空间:Pod中的多个容器能够访问同一个IP和端口范围;
-
IPC命名空间:Pod中的多个容器能够使用SystemV IPC或POSIX消息队列进行通信;
-
UTS命名空间:Pod中的多个容器共享一个主机名;
-
Volumes(共享存储卷):Pod中的各个容器可以访问在Pod级别定义的存储卷。
通常情况下,Docker依然执行它原本的任务,即管理容器和镜像。当Kubernetes把Pod调度到节点上,节点上的Kubelet会指示Docker启动特定的容器。接着,Kubelet会通过cgroup持续地收集容器的信息,然后提交到Kubernetes的管理面。Docker如往常一样拉取容器镜像、启动或停止容器。
K8S网络
Kubernetes网络包括网络模型、CNI、Service、Ingress、DNS等。在Kubernetes的网络模型中,每台服务器上的容器有自己独立的IP段,各个服务器之间的容器可以根据目标容器的IP地址进行访问。实现Kubernetes的容器网络重点需要关注两方面:IP地址分配和路由。
-
ip分配
·系统会从集群的VPC网络为每个节点分配一个IP地址。该节点IP用于提供从控制组件(如Kube-proxy和Kubelet)到Kubernetes Master的连接;
·系统会为每个Pod分配一个地址块内的IP地址。用户可以选择在创建集群时通过--pod-cidr指定此范围;
·系统会从集群的VPC网络为每项服务分配一个IP地址(称为ClusterIP)。大部分情况下,该VPC与节点IP地址不在同一个网段,而且用户可以选择在创建集群时自定义VPC网络。
-
Pod出站流量
Pod到Pod:CNI实现,每个Pod都有自己的IP地址,Pod之间都可以保持三层网络的连通性。
Pod到Service:Pod的生命周期很短暂,但客户需要的是可靠的服务,因此Kubernetes引入了新的资源对象Service,其实它就是 Pod前面的4层负载均衡器。Service总共有4种类型,其中最常用的类型是ClusterIP,这种类型的Service会自动分配一个仅集 群内部可以访问的虚拟IP。Kubernetes通过Kube-proxy组件实现这些功能,每台计算节点上都运行一个Kubeproxy进程,通过 复杂的iptables/IPVS规则在Pod和Service之间进行各种过滤和NAT。
Pod到集群外:从Pod内部到集群外部的流量,Kubernetes会通过SNAT来处理。SNAT做的工作就是将数据包的源从Pod内部的 IP:Port替换为宿主机的IP:Port。当数据包返回时,再将目的地址从宿主机的IP:Port替换为Pod内部的IP:Port,然后发送给Pod
“单Pod单IP”网络模型为我们勾勒了一个Kubernetes扁平网络的蓝图,在这个网络世界里:容器是一等公民,容器之间直接通信,不需要额外的NAT,因此不存在源地址被伪装的情况;Node与容器网络直连,同样不需要额外的NAT。扁平化网络的优点在于:没有NAT带来的性能损耗,而且可追溯源地址,为后面的网络策略做铺垫,降低网络排错的难度等。
总体而言,集群内访问Pod,会经过Service;集群外访问Pod,经过的是Ingress。
Kubernetes网络总体架构如图:
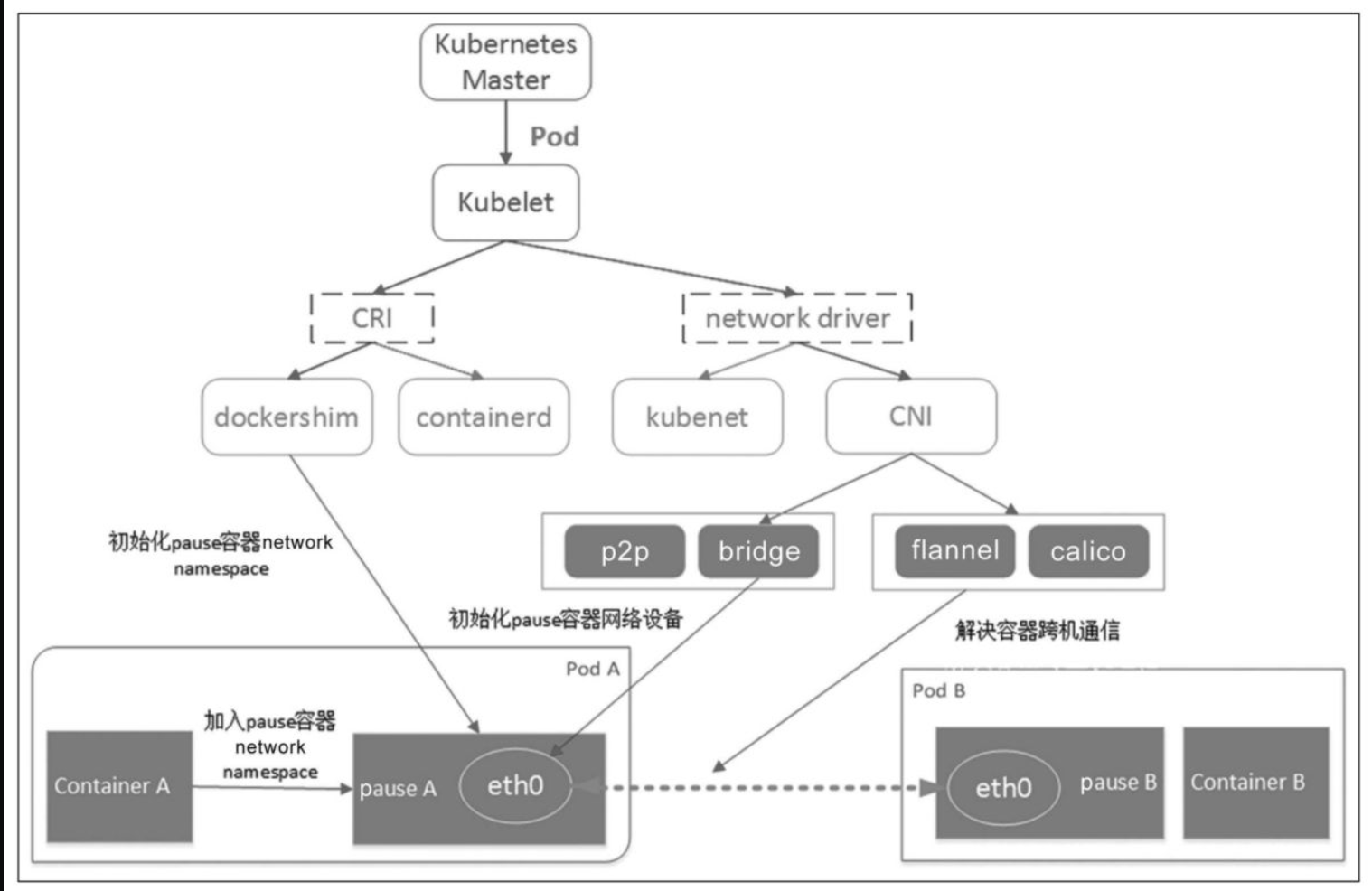
Kubernetes主机内容器的默认组网方案是bridge。flannel、Calico这些第三方插件解决容器之间的跨机通信问题,典型的跨机通信解决方案有bridge和overlay等。
Kubernetes经典的主机内组网模型是veth pair+bridge的方式。如果Kubernetes集群发生节点升级、修改Pod声明式配置、更新容器镜像或节点不可用,那么Kubernetes就会删除并重新创建Pod。
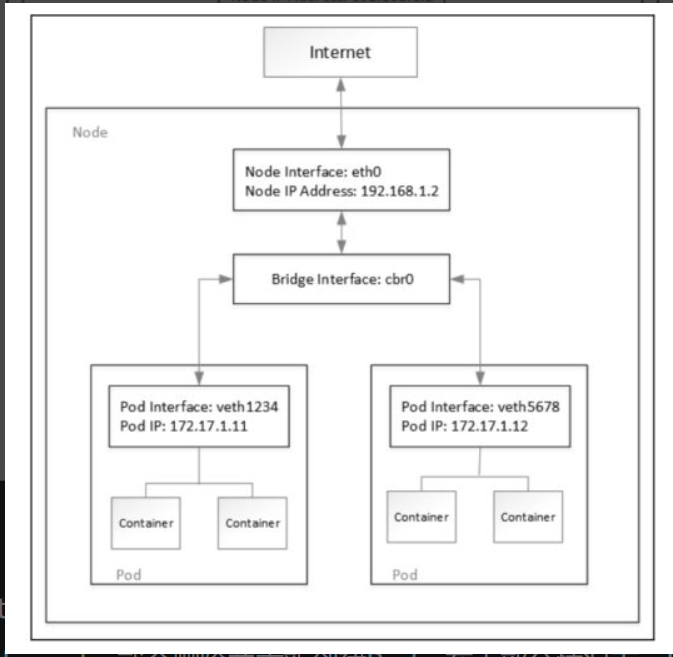
Kubernetes典型的跨机通信解决方案有bridge、overlay等。

pause容器
在容器中,必须要有一个进程充当每个PID namespace的init进程,使用Docker的话,ENTRYPOINT进程是init进程。如果多个容器之间共享PID namespace,那么拥有PID namespace的那个进程须承担init进程的角色,其他容器则作为init进程的子进程添加到PID namespace中。
pause容器运行着一个非常简单的进程,它不执行任何功能,基本上是永远“睡觉”的,但是它执行另一个重要的功能——即它扮演PID 1的角色,并在子进程成为“孤儿进程”的时候,通过调用wait()收割这些僵尸子进程。这样就不用担心我们的Pod的PID namespace里会堆满僵尸进程了。这也是为什么Kubernetes不随便找个容器(例如Nginx)作为父容器,让用户容器加入的原因。
在UNIX系统中,PID为1的进程是init进程,即所有进程的父进程。init进程比较特殊,它维护一张进程表并且不断地检查其他进程的状态。init进程的其中一个作用是当某个子进程由于父进程的错误退出而变成了“孤儿进程”,便会被init进程“收养”并在该进程退出时回收资源。
僵尸进程是已停止运行但进程表条目仍然存在的进程,父进程尚未通过wait系统调用进行检索。僵尸进程无法通过kill命令清除。init进程必须拥有“信号屏蔽”功能,不能处理某个信号逻辑,从而防止init进程被误杀。
访问服务
K8S在客户端和后端Pod之间引入一个抽象层Sercie来解决服务访问时的负载均衡,会话亲核性,健康检查,域名访问和容器迁移导致的IP变动。
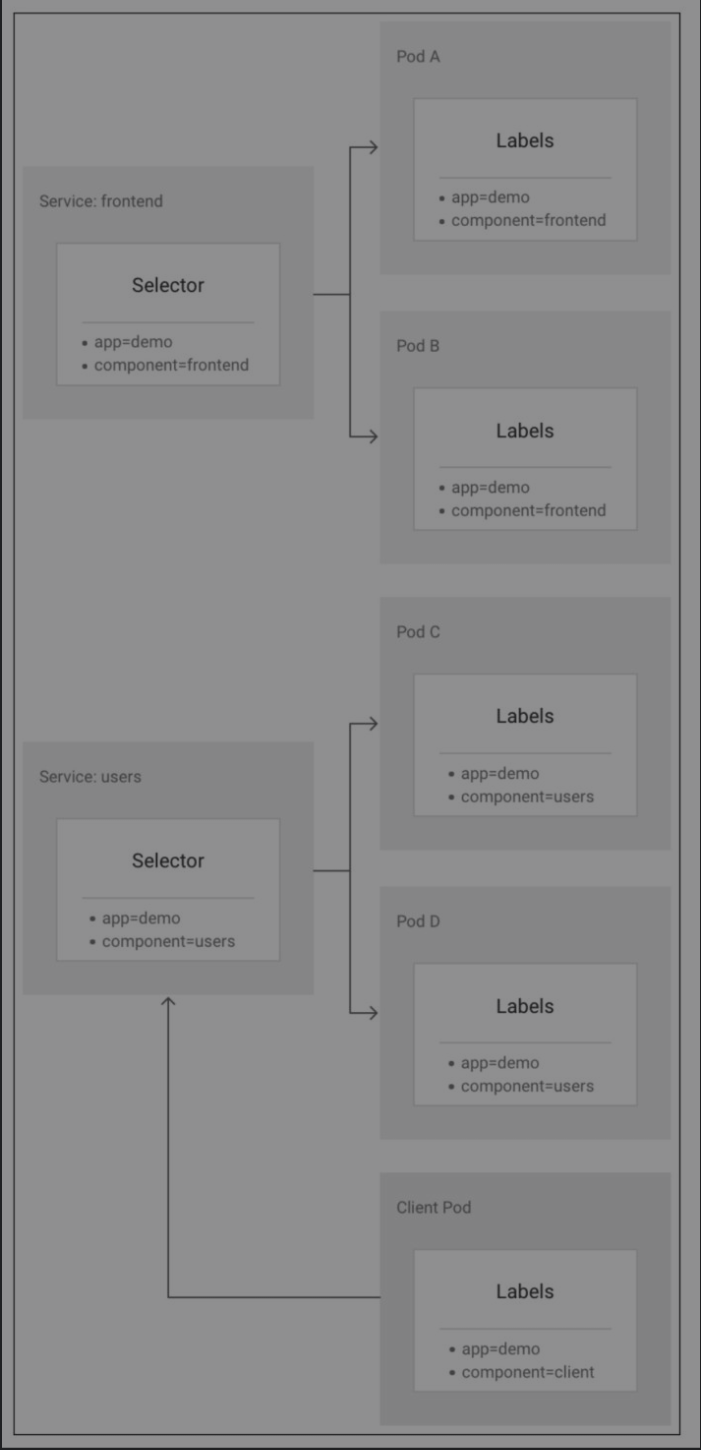
Kubernetes的Service代表的是Kubernetes后端服务的入口,它主要包含服务的访问IP(虚IP)和端口,因此工作在L4。
被Service选中的Pod,当它们运行且能对外提供服务后,Kubernetes的Endpoints Controller会生成一个新的Endpoints对象,记录Pod的IP和端口,这就解决了前文提到的后端实例健康检查问题。另外,Service的访问IP和Endpoints/Pod IP都会在Kubernetes的DNS服务器里存储域名和IP的映射关系,因此用户可以在集群内通过域名的方式访问Service和Pod。
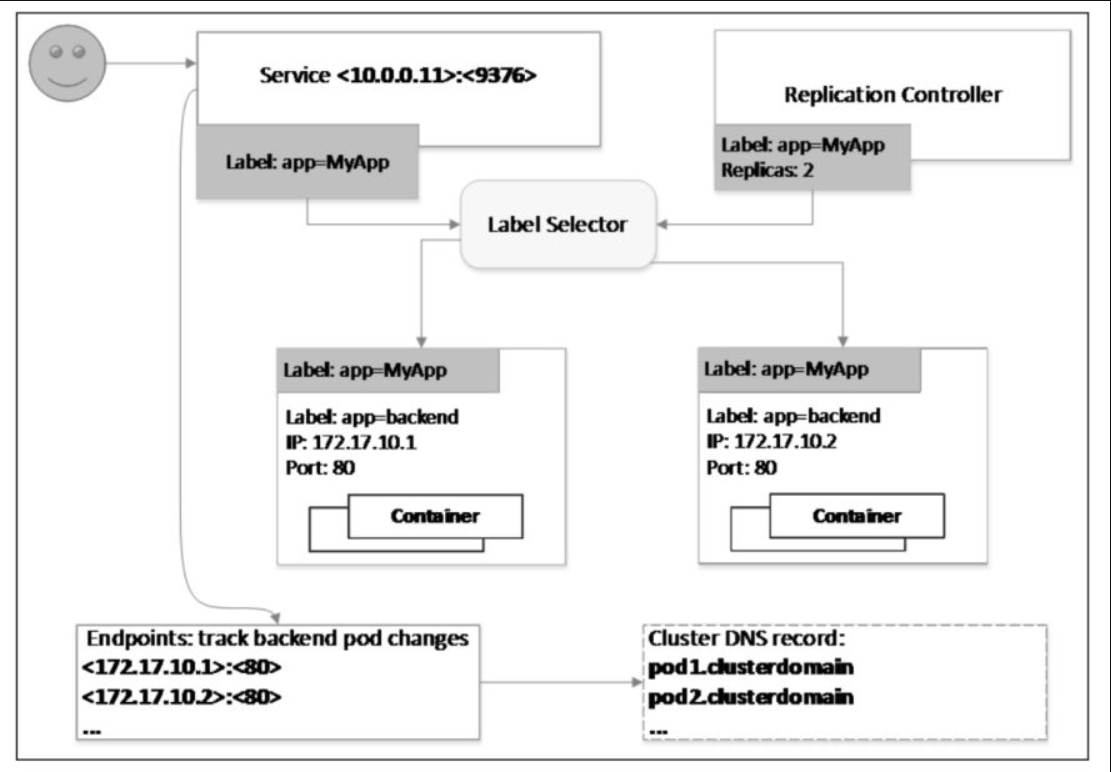
Kubernetes会从集群的可用服务IP池中为每个新创建的服务分配一个稳定的集群内访问IP地址,称为Cluster IP。Kubernetes还会通过添加DNS条目为Cluster IP分配主机名。Cluster IP和主机名在集群内是独一无二的,并且在服务的整个生命周期内不会更改。只有将服务从集群中删除,Kubernetes才会释放Cluster IP和主机名。用户可以使用服务的Cluster IP或主机名访问正常运行的Pod。
用户不用担心服务出现单点故障问题,Kubernetes会尽可能均匀地将流量分布到在多个节点上运行的Pod,因此一个或若干个(但不是所有)节点的服务中断情况不会影响服务的整体可用性。
Kubernetes使用Kube-proxy组件管理各服务与之后端Pod的连接,该组件在每个节点上运行。Kube-proxy是一个基于出站流量的负载平衡控制器,它监控Kubernetes API Service并持续将服务IP(包括Cluster IP等)映射到运行状况良好的Pod,落实到主机上就是iptables/IPVS等路由规则。访问服务的IP会被这些路由规则直接DNAT到Pod IP,然后走底层容器网络送到对应的Pod。
访问类型
Kubernetes Service有几种类型:Cluster IP、Load Balancer和NodePort。
-
Cluster IP
Cluster IP是默认类型,自动分配集群内部可以访问的虚IP——Cluster IP。我们随便创建一个Service,只要不做特别指定,都是Cluster IP类型。Cluster IP的主要作用是方便集群内Pod到Pod之间的调用。Cluster IP主要在每个node节点使用iptables,将发向Cluster IP对应端口的数据转发到后端Pod中。
-
Load Balancer
Load Balancer(简称LB)类型的Service需要Cloud Provider的支持。Kubernetes原生支持的Cloud Provider有GCE和AWS,因此和不同云平台的网络方案耦合较大,而且只能在特定的云平台上使用,局限性也较大。除了“外用”,Load Balancer还可以“内服”,即如果要在集群内访问Load Balancer类型的Service,则Kube-proxy用iptables或ipvs实现云服务提供商Load Balancer(一般都是L7的)的部分功能:L4转发、安全组规则等。
-
NodePort
NodePort类似Service,被称为乞丐版的Load Balancer类型Service,这也暗示了Node-Port Service可以用于集群外部访问Service,而且成本低廉(无须一个外部Load Balancer)。NodePort为Service在Kubernetes集群的每个节点上分配一个真实的端口,即NodePort。集群内/外部可基于集群内任何一个节点的IP:NodePort的形式访问Service。NodePort支持TCP、UDP、SCTP,默认端口范围是30000-32767,Kubernetes在创建NodePort类型Service对象时会随机选取一个。用户也可以在Service的spec.ports.nodePort中自己指定一个NodePort端口,就像指定ClusterIP那样。如果觉得默认端口范围不够用或者太大,可以修改API Server的--service-node-port-range的参数,修改默认NodePort的范围,例如--service-node-port-range=8000-9000。
NodePort的实现机制是Kube-proxy会创建一个iptables规则,所有访问本地NodePort的网络包都会被直接转发至后端Port。
在一般情况下,不建议用户自己指定NodePort,而是应该让Kubernetes选择,否则维护的成本会很高。
NodePort需要占用宿主机的端口。
配置详解见 Sercieve
集群外部访问服务
在Kubernets中,L7的转发功能、集群外访问Service,都是专门交给Ingress的。Ingress的作用就是在边界路由处开个口子,放外部流量进来。,它支持通过URL的方式将Service暴露到k8s集群外;支持自定义Service的访问策略;提供按域名访问的虚拟主机功能;支持TLS通信。
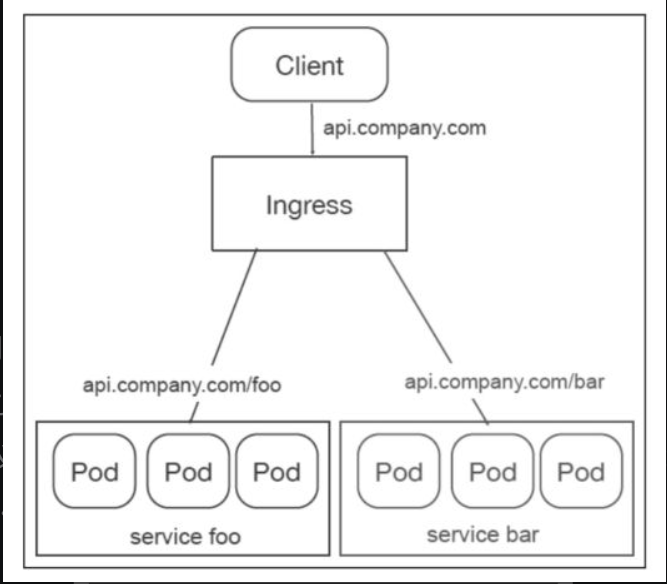
配置详解见 Ingress
Kubernetes的Ingress简单理解就是个规则定义,例如某个域名对应某个Service,即当某个域名的请求进来时,转发给某个Service。Ingress Controller负责实现这个规则,即Ingress Controller将其动态写入负载均衡器的配置中,从而实现服务的负载均衡。
域名解析:配置见
在一个Kubernetes集群中,DNS服务是非必需的,所以DNS服务以插件形式存在。
一般应用程序是无须感知DNS服务器的IP地址的,以Linux系统为例,容器内进程想要获得域名解析服务,只需把DNS Server写入/etc/resolv.conf文件。kubelet负责配置这个文件。
当Kubernetes的DNS服务Cluster IP分配后,系统(一般是指安装程序)会给Kubelet配置--cluster-dns=
对于Service,Kubernetes DNS服务器会生成三类DNS记录,分别是A记录、SRV记录和CNAME记录。
- A记录
A记录(A Record)是用于将域或子域指向某个IP地址的DNS记录的最基本类型。记录包括域名、解析它的IP地址和以秒为单位的TTL。TTL代表生存时间,是DNS记录上的一种到期日期。每个TTL都会告诉DNS服务器,它应该在其缓存中保留给定记录多长时间。
普通A记录:DNS自动设置为集群特定IP。
## service_name:Service名,namespace:Service所在namespace;·domain:提供的域名后缀,是Kubelet通过--cluster-domain配置的, ## 比如默认的cluster.local。在Pod中可以通过域名{service name}.{service namespace}.svc.{domain}访问任何服务,也可以使用缩写{service name}.{servicenamespace}直接访问。 ## 如果Pod和Service在同一个namespace中,那么甚至可以直接使用{service name}访问。 {service name}.{service namespace}.svc.{domain} -> Cluster IPheadless Service的A记录:DNS不自动设置解析为特定IP,而是由客户端获取IP组进行处理。
{service name}.{service namespace}.svc.{domain} -> 后端Pod IP列表如果在Pod Spec指定hostname和subdomain,那么Kubernetes DNS会额外生成Pod的A记录:
{hostname}.{subdomian}.{pod namespace}.pod.cluster.local -> Pod IP
-
SRV记录
SRV记录是通过描述某些服务协议和地址促进服务发现的。SRV记录通常定义一个符号名称和作为域名一部分的传输协议(如TCP),并定义给定服务的优先级、权重、端口和目标。
## sip是服务的符号名称,_tcp是服务的使用传输协议。记录内容代表:两个记录都定义了10的优先级。 ## 另外,第一个记录的权重为70,第二个记录的权重为20。 ## 优先级和权重通常用于建议指定使用某些服务器。记录中的最后两个值定义了要连接的端口和主机名,以便与服务通信。 _sip._tcp.example.com. 3600 IN SRV 10 70 5060 srvrecord.example.com _sip._tcp.example.com. 3600 IN SRV 10 20 5060 srvrecord2.ex -
CNAME记录
CNAME记录用于将域或子域指向另一个主机名。为此,CNAME使用现有的A记录作为其值。相反,A记录会解析为指定的IP地址。此外,在Kubernetes中,CNAME记录可用于联合服务的跨集群服务发现。在整个场景中会有一个跨多个Kubernetes集群的公共服务。所有Pod都可以发现这项服务(无论这些Pod在哪个集群上)。这是一种跨集群服务发现方法。
Kubernetes域名解析策略:
None:从Kubernetes 1.9版本起引入的一个新选项值。它允许Pod忽略Kubernetes环境中的DNS设置。应使用dnsConfigPod规范中的字段提供所有DNS设置;
ClusterFirstWithHostNet:对于使用hostNetwork运行的Pod,用户应该明确设置其DNS策略为ClusterFirstWithHostNet;
ClusterFirst:任何与配置的群集域后缀(例如cluster.local)不匹配的DNS查询(例如“www.kubernetes.io”)将转发到从宿主机上继承的上游域名服务器。集群管理员可以根据需要配置上游DNS服务器;
Default:Pod从宿主机上继承名称解析配置。
网络策略
网络策略就是基于Pod源IP(所以Kubernetes网络不能随随便便做SNAT)的访问控制列表,限制的是Pod之间的访问。通过定义网络策略,用户可以根据标签、IP范围和端口号的任意组合限制Pod的入站/出站流量。网络策略作为Pod网络隔离的一层抽象,用白名单实现了一个访问控制列表(ACL),从Label Selector、namespace selector、端口、CIDR这4个维度限制Pod的流量进出。
K8S配置:
Pod
## 通过增加hostAliases字段添加自定义条目,功能类似修改容器的hosts文件(Pod启用了hostNetwork,此配置将失效)
apiVersion: v1
kind: Pod
metadata:
name: hostaliases-pod
namespace: default
annotations:
##限制流入流出速度,需要开启cni插件,在启动时 –network-plugin=cni,用户通过Pod的annotations下发带宽限制数值,
## CNI的bandwidth插件调用Linux流量控制插件tc,在宿主机上应用tc配置。
kubernetes.io/ingress-bandwidth: 1M
kubernetes.io/egress-bandwidth: 1M
spec:
## 开启共享PID namespace
shareProcessNamespace: true
## 配置hosts
hostAliases:
- ip: "127.0.0.1"
hostnames:
- "foo.local"
- "bar.local"
- ip: "10.1.2.3"
hostnames:
- "foo.remote"
- "bar.remote"
---
## 配置Node类型得到dnsPolicy
dnsPolicy: "Node"
dnsConfig:
nameservers:
- 1.2.3.4
searches:
- ns1.svc.cluster.local
- my.dns.search.suffix
options:
- name: ndots
value: "2"
- name: edns0
---
## 配置ClusterFirstWithHostNet类型得到dnsPolicy,Pod使用主机网络(hostNetwork:true)时,
## DNS策略需要设置成ClusterFirstWithHostNet。
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
---
## ClusterFirst;ClusterFirst策略就是优先使用Kubernetes的DNS服务解析,失败后再使用外部级联的DNS服务解析
dnsPolicy: ClusterFirst
---
containers:
- name: cat-hosts
image: busybox
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
restarPolicy: AlwaysService
apiVersion: v1
kind: Service
metadata:
labels:
name: nginx
role: service
name: nginx-service
namespace: defalut
spec:
## Cluster IP、Load Balancer和NodePort,默认为Cluster IP;
type: NodePort/LoadBalancer/ClusterIp
## 增加访问亲和度,配置3小时内同客户端请求转发到同一服务器,默认为none。
sessionAffinity: ClientIP
## 指定流量转到同一节点上的Pod,避免流量跳转;默认为Cluster,
## externalTrafficPolicy只支持NodePort和Load Balancer的Service。externalTrafficPolicy的设定是当流量到达确定的节点后,再由Kube-proxy在该节点上找Service的Endpoint。有些节点上存在Service Endpoint,有些则没有,再配合Kube-proxy的健康检查就能确定哪些节点上有符合要求的后端Pod。
## 访问NodePort和Load Balancer都能指定节点,但Cluster IP无法指定节点,因此Service流量就永远出不了发起访问的客户端的那个节点,这也不是externalTrafficPolicy这个特性的设计初衷。
externalTrafficPolicy: Local
## 虚拟IP,如果不指定,K8S会自动从配置范围中随机分配,虚拟IP无法PING通。此处为IP+PORT共同决定服务;
clusterIP: 100.101.28.148
selector:
## 匹配app=nginx的Pod
app: nginx
ports:
- name: http
## 默认TCP,支持TCP/UDP/SCTP
protocal: TCP
## 暴露访问端口
port: 80
## 集群外部访问Service入口的一种方式,Load Balancer/NodePort
nodePort: 30062
## Pod端口
targetPort: 8080
selector:
ssh-service: "true"Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: whoami
spec:
selector:
matchLabels:
run: whoami
replicas: 2
template:
metadata:
labels:
run: whoami
spec:
containers:
- name: whoami
image: whoami:v1
ports:
- containerPort: 3000Ingress
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
spec:
## 自定义策略,/foo转发到s1:80的service,/bar转发到s2:80的service;如果不配置rules,则所有流量都转发给BACKEND
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
backend:
serviceName: s1
servicePort: 80
- path: /bar
backend:
serviceName: s2
servicePort: 80
tls:
- secretName: testsecret
backend:
serviceName: testsvc
servicePort: 80NetworkPolicy
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
## default-deny/allow-all
name: default-deny
namespace: default
spec:
podSelector:
matchLabels:
app: bookstore
role: api
## Deny all ingress and egress
policyTypes:
- Ingress
- Egress
## Allow all ingress {}代表允许所有,[]代表拒绝所有
ingress:
## 限制进入的端口
- ports:
- protocal: TCP
port: 6379
- from:
## 限制部分流量进入,配置相应的label,所有default namespace下的包含app=bookstore&role=api Labels的Pod
- podSelector:
matchLabels:
app: bookstore
role: api
## 只允许特定namespace的Pod流量进入
- namespaceSelector:
matchLabels:
purpose: production
## project=myproject Labels的namespace中的Pod
project: myproject
## ip限制
- ipBlock:
## 所有172.17.0.0/16网段的IP,除了172.17.1.0/24中的Ip
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
## Allow all egress
egress:
- to:
## 允许访问网段为10.0.0.0/24的Ip的5978端口
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
k8s命令:
kubectl get pod
kubectl get endpoints
## deployment创建服务
kubectl expose deployment/whoami
## service创建服务
kubectl create -f service.yaml
## 获取所有service详情
kubectl get svc
## 获取service详情
kubectl describe service redis-sentinel
## 查看某个服务的细节,可以使用cluster-ip进行内部访问,使用external-ip进行外部访问
kubectl get svc influxdb
:
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
influxdb 10.97.121.42 10.13.242.236 8086/TCP 39s
## 查看监听端口
lsof -i:9000
## 查看ingress,address为访问入口,由Ingress Controller分配;
## BACKEND是Ingress对接的后端Kubernetes Service IP+Port;RULE是自定义的访问策略,主要基于URL的转发策略,若为空,则访问ADDRESS的所有流量都转发给BACKEND。
## 当arress为空时,说明底层的LoadBalancer未就绪。
kubectl get ingress test-ingress
:
NAME RULE BACKEND ADDRESS
test - testsvc:80 107.178.254.228
:
NAME RULE BACKEND ADDRESS
test foo.bar.com
/foo s1:80
/bar s2:80
## 创建whoami服务,做如下域名解析,会在DNS的配置中增加解析,
## DNS Server的IP地址是10.0.0.1。
## options ndots:5的含义是当查询的域名字符串内的点字符数量超过ndots(5)值时,则认为是完整域名,直接解析,
## 否则Linux系统会自动尝试用default.pod.cluster.local、default.svc.cluster.local或svc.cluster.local补齐域名后缀.
## 运行DNS Pod可能需要特权,即配置Kubelet的参数:--allow-privileged=true。
kubectl exec -ti busybox -- nslookup kubernetes.default
kubectl exec -ti busybox -- nslookup whoami
kubectl exec -ti busybox -- nslookup whoami.default.svc
kubectl exec -ti busybox -- nslookup whoami.default.svc.tracswarp.local
cat /etc/resolv.conf
:
search default.pod.cluster.local default/svc.cluster.local svc.cluster.local cluster.local
nameserver 10.0.0.1
options ndots:5
options ndots:5
## 调试DNS,DNS失败,通常会得到如下响应:
kubectl exec -ti busybox -- nslookup kubernetes.default
:
Server: 10.0.0.10
Address 1: 10.0.0.10
nslookup: can`t resolve 'kubernetes.default'
## 检查DNS配置是否正确。
kubectl exec test-deployment-84dc998fc5-772gj cat /etc/resolv.conf
:
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
## 如果/etc/resolve.conf的所有条目都是正确的,则需要检查kube-dns/coredns插件是否已启用,
## 或者检查kubedns/coredns Pod是否正在运行。如果Pod正在运行,则全局DNS服务可能存在问题。
kubectl get svc --namespacke=kube-system
:
NAME TYPE CLUSTER-IP EXTRERNAL-IP PORT(S)
AGE
kube-dns ClusterIP 10.96.0.10 <node> 53/UDP,53
## 检查DNS Endpoint是否准备好
kubectl get ep kube-dns --namespace=kube-system
:
NAME EDNPOINTS AGE
kube-dns 172.17.0.5:53,172.17.0.5:53 133ddocker命令:
##查看指定时间后的日志,只显示最后100行:
$ docker logs -f -t --since="2018-02-08" --tail=100 CONTAINER_ID
##查看最近30分钟的日志:
$ docker logs --since 30m CONTAINER_ID
查看某时间之后的日志:
$ docker logs -t --since="2018-02-08T13:23:37" CONTAINER_ID
## 查看某时间段日志:
$ docker logs -t --since="2018-02-08T13:23:37" --until "2018-02-09T12:23:37" CONTAINER_ID参考:
《Kubernete网络权威指南》