关于数据库变长字段索引问题
以下问题已经测试数据来源于网上,只是针对问题做补充。
Mysql中Varchar(50)和varchar(500)区别是什么?
一. 问题描述
我们在设计表结构的时候,设计规范里面有一条如下规则:
- 对于可变长度的字段,在满足条件的前提下,尽可能使用较短的变长字段长度。
为什么这么规定,我在网上查了一下,主要基于两个方面
- 基于存储空间的考虑
- 基于性能的考虑
网上说Varchar(50)和varchar(500)存储空间上是一样的,真的是这样吗?
基于性能考虑,是因为过长的字段会影响到查询性能?
本文我将带着这两个问题探讨验证一下
二.验证存储空间区别
1.准备两张表
CREATE TABLE `category_info_varchar_50` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(50) NOT NULL COMMENT '分类名称',
`is_show` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否展示:0 禁用,1启用',
`sort` int(11) NOT NULL DEFAULT '0' COMMENT '序号',
`deleted` tinyint(1) DEFAULT '0' COMMENT '是否删除',
`create_time` datetime NOT NULL COMMENT '创建时间',
`update_time` datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_name` (`name`) USING BTREE COMMENT '名称索引'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='分类';
CREATE TABLE `category_info_varchar_500` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(500) NOT NULL COMMENT '分类名称',
`is_show` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否展示:0 禁用,1启用',
`sort` int(11) NOT NULL DEFAULT '0' COMMENT '序号',
`deleted` tinyint(1) DEFAULT '0' COMMENT '是否删除',
`create_time` datetime NOT NULL COMMENT '创建时间',
`update_time` datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_name` (`name`) USING BTREE COMMENT '名称索引'
) ENGINE=InnoDB AUTO_INCREMENT=288135 DEFAULT CHARSET=utf8mb4 COMMENT='分类';2.准备数据
给每张表插入相同的数据,为了凸显不同,插入100万条数据
DELIMITER $$
CREATE PROCEDURE batchInsertData(IN total INT)
BEGIN
DECLARE start_idx INT DEFAULT 1;
DECLARE end_idx INT;
DECLARE batch_size INT DEFAULT 500;
DECLARE insert_values TEXT;
SET end_idx = LEAST(total, start_idx + batch_size - 1);
WHILE start_idx <= total DO
SET insert_values = '';
WHILE start_idx <= end_idx DO
SET insert_values = CONCAT(insert_values, CONCAT('(\'name', start_idx, '\', 0, 0, 0, NOW(), NOW()),'));
SET start_idx = start_idx + 1;
END WHILE;
SET insert_values = LEFT(insert_values, LENGTH(insert_values) - 1); -- Remove the trailing comma
SET @sql = CONCAT('INSERT INTO category_info_varchar_50 (name, is_show, sort, deleted, create_time, update_time) VALUES ', insert_values, ';');
PREPARE stmt FROM @sql;
EXECUTE stmt;
SET @sql = CONCAT('INSERT INTO category_info_varchar_500 (name, is_show, sort, deleted, create_time, update_time) VALUES ', insert_values, ';');
PREPARE stmt FROM @sql;
EXECUTE stmt;
SET end_idx = LEAST(total, start_idx + batch_size - 1);
END WHILE;
END$$
DELIMITER ;
CALL batchInsertData(1000000);3.验证存储空间
查询第一张表SQL
SELECT
table_schema AS "数据库",
table_name AS "表名",
table_rows AS "记录数",
TRUNCATE ( data_length / 1024 / 1024, 2 ) AS "数据容量(MB)",
TRUNCATE ( index_length / 1024 / 1024, 2 ) AS "索引容量(MB)"
FROM
information_schema.TABLES
WHERE
table_schema = 'test_mysql_field'
and TABLE_NAME = 'category_info_varchar_50'
ORDER BY
data_length DESC,
index_length DESC;查询结果

查询第二张表SQL
SELECT
table_schema AS "数据库",
table_name AS "表名",
table_rows AS "记录数",
TRUNCATE ( data_length / 1024 / 1024, 2 ) AS "数据容量(MB)",
TRUNCATE ( index_length / 1024 / 1024, 2 ) AS "索引容量(MB)"
FROM
information_schema.TABLES
WHERE
table_schema = 'test_mysql_field'
and TABLE_NAME = 'category_info_varchar_500'
ORDER BY
data_length DESC,
index_length DESC;查询结果

4.结论
两张表在占用空间上确实是一样的,并无差别
三.验证性能区别
1.验证索引覆盖查询
select name from category_info_varchar_50 where name = 'name100000'
-- 耗时0.012s
select name from category_info_varchar_500 where name = 'name100000'
-- 耗时0.012s
select name from category_info_varchar_50 order by name;
-- 耗时0.370s
select name from category_info_varchar_500 order by name;
-- 耗时0.379s通过索引覆盖查询性能差别不大
1.验证索引查询
select * from category_info_varchar_50 where name = 'name100000'
--耗时 0.012s
select * from category_info_varchar_500 where name = 'name100000'
--耗时 0.012s
select * from category_info_varchar_50 where name in('name100','name1000','name100000','name10000','name1100000',
'name200','name2000','name200000','name20000','name2200000','name300','name3000','name300000','name30000','name3300000',
'name400','name4000','name400000','name40000','name4400000','name500','name5000','name500000','name50000','name5500000',
'name600','name6000','name600000','name60000','name6600000','name700','name7000','name700000','name70000','name7700000','name800',
'name8000','name800000','name80000','name6600000','name900','name9000','name900000','name90000','name9900000')
-- 耗时 0.011s -0.014s
-- 增加 order by name 耗时 0.012s - 0.015s
select * from category_info_varchar_50 where name in('name100','name1000','name100000','name10000','name1100000',
'name200','name2000','name200000','name20000','name2200000','name300','name3000','name300000','name30000','name3300000',
'name400','name4000','name400000','name40000','name4400000','name500','name5000','name500000','name50000','name5500000',
'name600','name6000','name600000','name60000','name6600000','name700','name7000','name700000','name70000','name7700000','name800',
'name8000','name800000','name80000','name6600000','name900','name9000','name900000','name90000','name9900000')
-- 耗时 0.012s -0.014s
-- 增加 order by name 耗时 0.014s - 0.017s索引范围查询性能基本相同, 增加了order By后开始有一定性能差别;
3.验证全表查询和排序
全表无排序


全表有排序
select * from category_info_varchar_50 order by name ;
--耗时 1.498s
select * from category_info_varchar_500 order by name ;
--耗时 4.875s

结论:
全表扫描无排序情况下,两者性能无差异,在全表有排序的情况下, 两种性能差异巨大;
分析原因
varchar50 全表执行sql分析
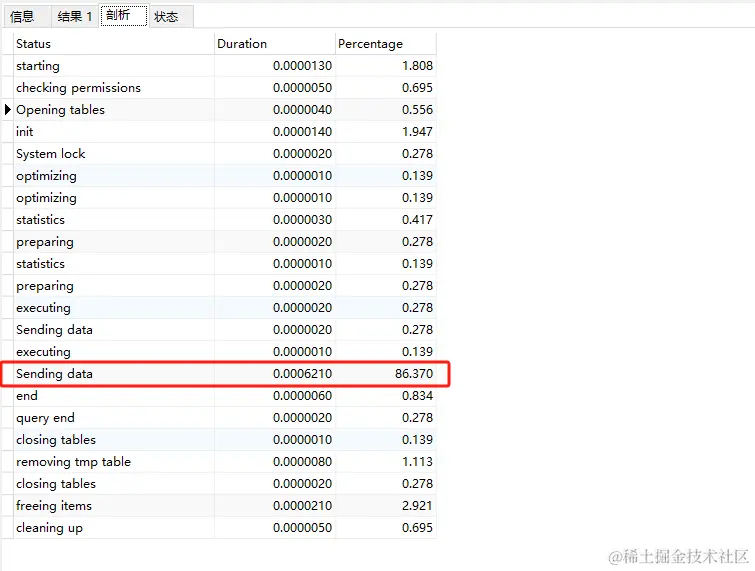
我发现86%的时花在数据传输上,接下来我们看状态部分,
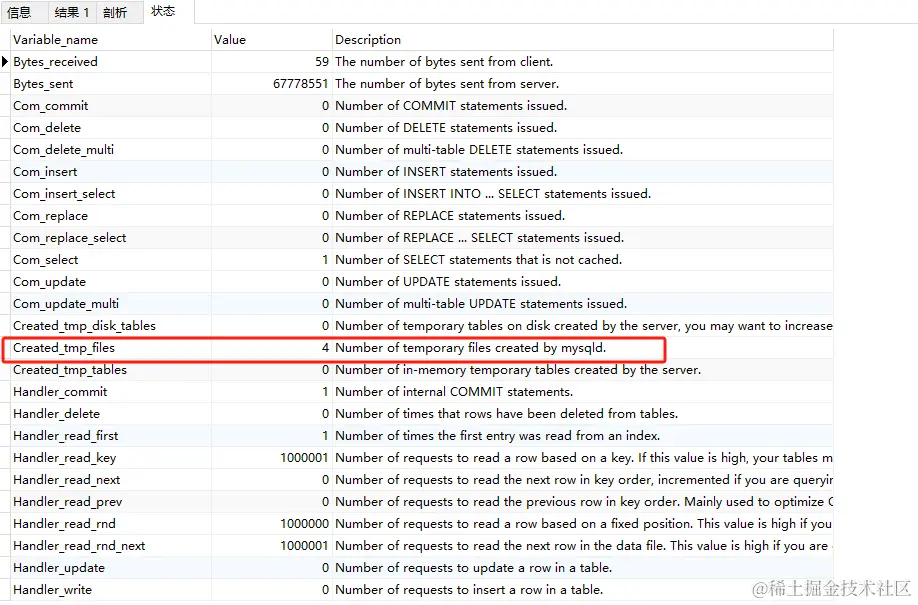
关注Created_tmp_files和sort_merge_passes 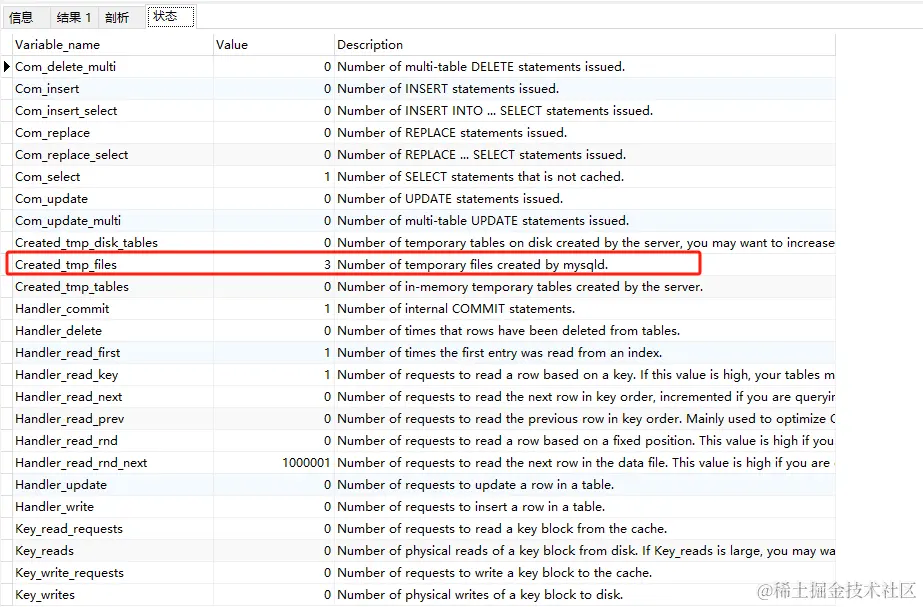
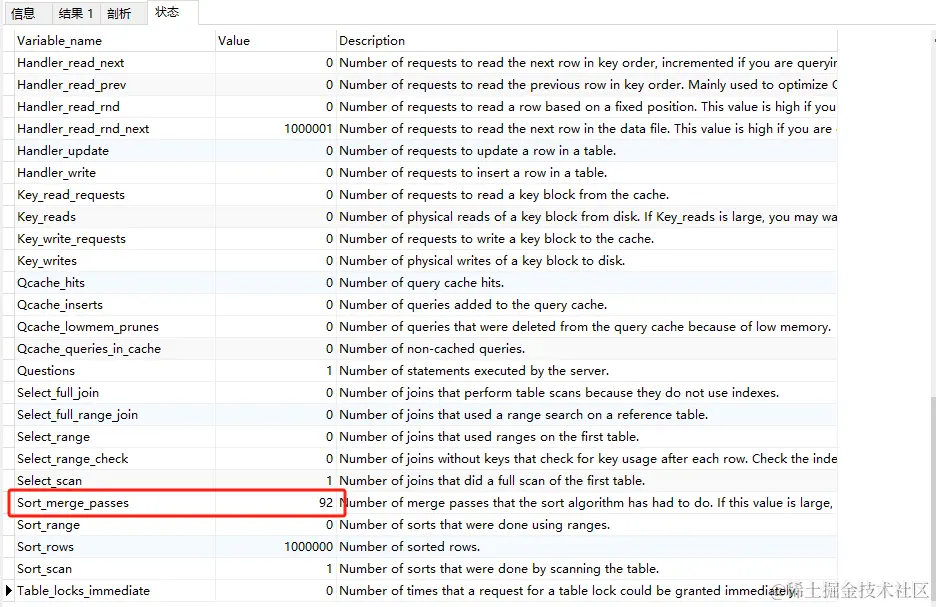
Created_tmp_files为3
sort_merge_passes为95
varchar500 全表执行sql分析
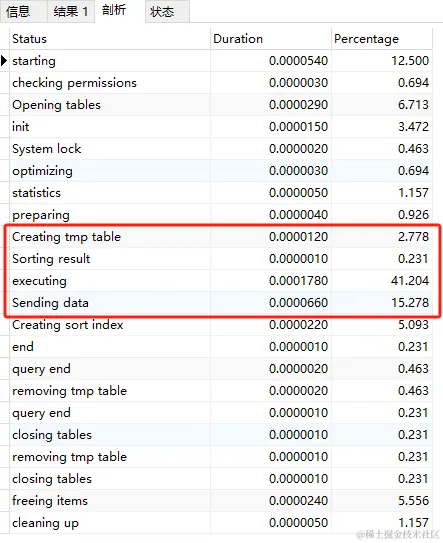
增加了临时表排序
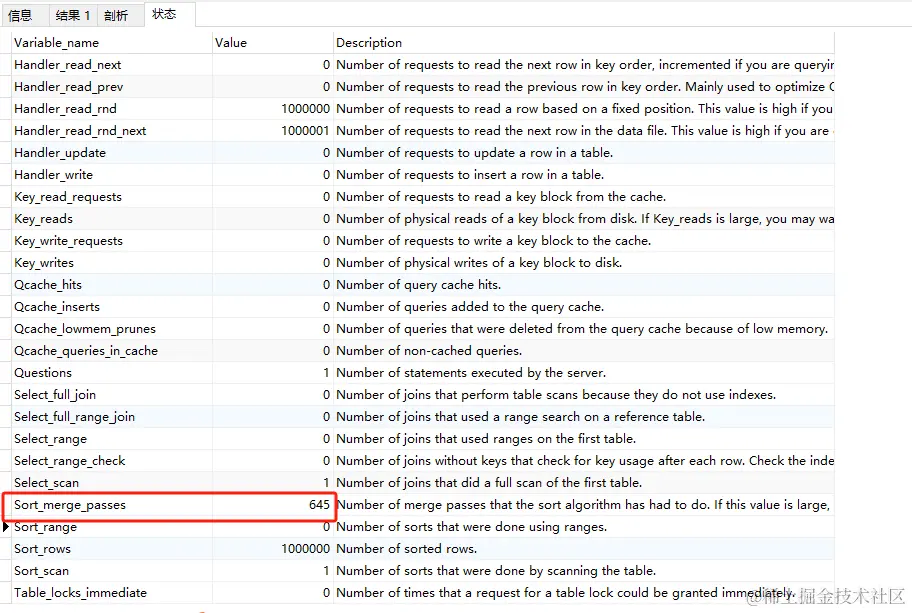
Created_tmp_files 为 4
sort_merge_passes为645
关于sort_merge_passes, Mysql给出了如下描述:
Number of merge passes that the sort algorithm has had to do. If this value is large, you may want to increase the value of the sort_buffer_size.
其实sort_merge_passes对应的就是MySQL做归并排序的次数,也就是说,如果sort_merge_passes值比较大,说明sort_buffer和要排序的数据差距越大,我们可以通过增大sort_buffer_size或者让填入sort_buffer_size的键值对更小来缓解sort_merge_passes归并排序的次数。
个人补充
select * from category_info_varchar_50 order by name ;这个sql会经历以下几个过程:
- 查询首先被解析并判断是否合法
- 然后被重写,去除了无用的操作并且加入预优化部分
- 接着被优化以便提升性能,并被转换为可执行代码和数据访问计划。
- 然后计划被编译
- 最后,被执行
我们知道--->所有的现代数据库都在用基于成本的优化(即CBO)来优化查询。道理是针对每个运算设置一个成本,通过应用成本最低廉的一系列运算,来找到最佳的降低查询成本的方法。
这里select *`需要回表,无法进行索引覆盖,而排序字段使用的是`name`,如果使用`name`上面的索引进行排序查询,每一次排序都需要回表查询数据,回表查询io次数过多,会很慢。而如果是全表扫描并进行内存排序(如果内存足够)`[如果能在工作内存中放下所有元组,那么排序操作会选用快速排序算法。否则就会创建临时文件,使用文件归并排序算法。]
所以如果统计信息正常的话这里执行计划大概率会选择全表扫描。
针对这部分的内容可以查看:关系型数据库是如何工作的
上面的结果也正是全表扫描,这个时候如果没有任何聚合排序处理内存里面只会存储真实数据大小的数据集;上面的例子使用了排序,进而使用了临时表对数据进行排序处理,那么这个时候变长字段的处理就成为了这次例子的主题。
来看看官方文档:MySQL中的内部临时表使用
(Mysql-8
The internal_tmp_mem_storage_engine variable defines the storage engine used for in-memory internal temporary tables. Permitted values are TempTable (the default) and MEMORY.
When in-memory internal temporary tables are managed by the TempTable storage engine, rows that include VARCHAR columns, VARBINARY columns, and other binary large object type columns (supported as of MySQL 8.0.13) are represented in memory by an array of cells, with each cell containing a NULL flag, the data length, and a data pointer. Column values are placed in consecutive order after the array, in a single region of memory, without padding. Each cell in the array uses 16 bytes of storage. The same storage format applies when the TempTable storage engine allocates space from memory-mapped files.
When in-memory internal temporary tables are managed by the MEMORY storage engine, fixed-length row format is used. VARCHAR and VARBINARY column values are padded to the maximum column length, in effect storing them as CHAR and BINARY columns.
(Mysql-5.7
The internal_tmp_disk_storage_engine variable defines the storage engine the server uses to manage on-disk internal temporary tables. Permitted values are INNODB (the default) and MYISAM.
In-memory temporary tables are managed by the MEMORY storage engine, which uses fixed-length row format. VARCHAR and VARBINARY column values are padded to the maximum column length, in effect storing them as CHAR and BINARY columns.
大致意思是:
(Mysql-8
允许的值为 TempTable(默认值)和 MEMORY
当存储引擎管理内存中的内部临时表时 TempTable,包含 VARCHAR列、 VARBINARY列和其他二进制大对象类型列(自 MySQL 8.0.13 起受支持)的行在内存中由单元格数组表示,每个单元格包含一个 NULL 标志、数据长度和一个数据指针。列值按连续顺序放置在数组之后的单个内存区域中,没有填充。数组中的每个单元格使用 16 个字节的存储空间。当TempTable存储引擎从内存映射文件分配空间时,适用相同的存储格式。
当存储引擎管理内存中的内部临时表时 MEMORY,使用固定长度的行格式。VARCHAR和 VARBINARY列值被填充到最大列长度,实际上将它们存储为 CHAR和BINARY列。
(Mysql-5.7
允许的值为 INNODB(默认值)和 MYISAM。
内存临时表由 MEMORY使用固定长度行格式的存储引擎管理。VARCHAR和 VARBINARY列值被填充到最大列长度,实际上将它们存储为 CHAR和BINARY列。在8.0以后使用的TempTable`,而它使用的是真实的数据长度;`5.7`使用的`Innodb`默认,使用的是`MEMORY
所以上面例子中大概率是5.7
在 PostgreSQL 中,VARCHAR 字段在临时表中的存储方式与 MySQL 的行为类似,依然会存储实际长度,而不会占用定义的最大长度。具体方案如下:
PostgreSQL 对 VARCHAR 字段的处理
1. VARCHAR 存储方式
- 变长字段:
VARCHAR(N)在 PostgreSQL 中本质上是一个变长字段,存储实际数据的长度,不会占用最大定义的长度空间。字段前会有 1 到 4 个字节(视数据长度而定)作为长度前缀,表示该字段的实际长度。 - 例如,对于一个定义为
VARCHAR(50)的字段,如果存储的是 10 个字符,实际存储的就是这 10 个字符,再加上用于记录长度的字节(通常是 1 个字节)。
2. 临时表中的存储方式
PostgreSQL 在使用临时表时,和普通表一样,VARCHAR 字段始终是变长的。因此,无论临时表是存储在内存还是磁盘,VARCHAR 字段都只会存储实际使用的字符长度,而不会按照定义的最大长度进行存储。
3. 临时表的类型
在 PostgreSQL 中,临时表(temporary tables)通常存储在磁盘上,除非特定查询可以完全在内存中执行。即便是在内存中执行,VARCHAR 字段依然是变长的,并按实际长度存储。
在 Oracle 中,VARCHAR2 字段的存储方式与 PostgreSQL 和 MySQL 相似,具体行为如下:
1. VARCHAR2 存储方式
- 变长字段:在 Oracle 中,
VARCHAR2是一个变长字段。它存储的是实际的字符数据长度,而不是定义的最大长度。 - 对于每个
VARCHAR2(N)字段,Oracle 会根据存储的实际字符数量来分配空间,并且会有 1 到 3 个字节的长度前缀(视实际数据长度而定)来记录这个字段的实际长度。 - 例如,如果
VARCHAR2(50)字段存储了 10 个字符,Oracle 会仅存储这 10 个字符,再加上用于表示长度的几个字节。
2. 临时表中的存储方式
在 Oracle 中,临时表与普通表的字段存储规则相同,即 VARCHAR2 字段在临时表中依然会按实际长度存储,而不会占用定义的最大长度。临时表的字段不会转换为固定长度。
3. 临时表的类型
Oracle 临时表有两种主要类型:
- 会话级别临时表(
ON COMMIT PRESERVE ROWS):数据在当前会话中有效,当会话结束时清除。 - 事务级别临时表(
ON COMMIT DELETE ROWS):在每次事务提交后清除数据。
无论临时表类型如何,VARCHAR2 字段在表中都只存储实际使用的字符长度。
4. 内存和磁盘的临时表管理
Oracle 对临时表的处理会基于查询的规模和系统资源:
- 如果数据量较小,且系统内存足够,临时表可能完全驻留在内存中,处理速度更快。
- 当数据量较大时,临时表会部分或全部存储到磁盘中。但即使写入磁盘,
VARCHAR2依然是按实际长度存储,不会转换为固定长度字段。